

Apache Spark is an absolute powerhouse when it comes to open-source Big Data processing and analytics. It’s used all over the place for everything from data processing to machine learning to real-time stream processing. Thanks to its distributed architecture, it can parallelize workloads like nobody’s business, making it a lean, mean data processing machine when it comes to tackling those truly massive data sets.
So, what’s the deal with Spark? In this article, we’re going to give you a rundown of its key concepts and architecture. First things first, we’ll provide a high-level overview of Spark, including its standout features. We’ll even throw in a comparison to Apache Hadoop, another popular open-source Big Data processing engine, just for good measure.
From there, we’ll dive into the nitty-gritty of Spark’s architecture. You’ll learn all about how it divides up tasks and data among a cluster of machines, all optimized for top-notch performance when dealing with massive workloads. This is the stuff you need to know to get the most out of Spark, and we’re going to deliver it straight to you in plain language that anyone can understand.
By the end of this article, you’ll be well-equipped to get started with Apache Spark, armed with a solid understanding of its core concepts and architecture. You’ll know exactly how it works and how to use it to process and analyze those gargantuan data sets that would make other Big Data processing engines run for the hills. So let’s get started and unleash the power of Apache Spark!
What Makes Apache Spark so Successful?
Spark has been able to catch a lot of attention in recent years. Due to growing data volumes, more companies are using Apache Spark to handle their steadily increasing data. Companies that use Apache Spark include Amazon, Netflix, Disney, and even NASA. NASA uses Spark to process a data flow of many TB/s that comes from all of their earth monitoring instruments and space observatories around the globe (more on the NASA webpage). Pretty cool, right?
There are various reasons for Spark’s success. One reason is scalability. Spark has been consistently optimized for parallel computation in scalable distributed systems. Its architecture scales with the workload, thus allowing it to handle different workloads efficiently. This is important as companies want to scale their usage of resources in the cloud depending on use case-specific needs.
Another reason is Spark’s versatility of use. Spark supports diverse workloads, including batch processing and streaming, machine learning, and SQL analytics. In addition, Spark supports various data types and storage formats, further increasing its versatility and use in different domains. The unique combination of several features and capabilities makes Apache Spark an exciting piece of technology and creates a strong demand for Spark knowledge in the market.
Also: Leveraging Distributed Computing for Weather Analytics with PySpark

Spark Features
Spark was initially launched in 2009 by Matei Zaharia at UC Berkeley’s AMPLab. It was later released as open-source under a BSD license in 2010. Since 2013, Spark has been part of the Apache Software Foundation, which currently (2022) lists it as a top-priority project. Key features of the Spark ecosystem are:
- In-Memory Processing: Spark is designed for in-memory computations to avoid writing data to disk and achieve high speed.
- Open Source: The development and promotion of Spark are driven by a growing community of practitioners and researchers.
- Reusability: Spark promotes code reuse through standard functions and method piling.
- Fault Tolerance: Spark comes with built-in fault tolerance, making Spark resilient against outtakes of cluster nodes.
- Real-time Streaming: Spark provides enhanced capabilities for real-time streaming of big data.
- Compatibility: Spark integrates well with existing big-data technologies such as Hadoop and offers support for various programming languages, incl. R, Python, Scala, and Java.
- Built-in Optimization: Spark has a built-in optimization engine. It is based on the lazy evaluation paradigm and uses acyclic-directed graphs (DAG) to create execution plans that optimize transformations.
- Analytics-ready: Spark provides powerful libraries for querying structured data inside Spark, using either SQL or DataFrame API. In addition, Spark comes with ML Flow, an integrated library for machine learning that can execute large ML workloads in memory.
Spark combines these features and provides a one-stop-shop solution, thus making it extremely powerful and versatile.
.
Local vs. Distributed Computing
To understand how Spark works, it’s helpful to compare a local system to a distributed computing system. While a local system can handle smaller workloads, it has several limitations when it comes to Big Data processing.
One limitation is the number of cores. Modern CPUs typically have at least two processing cores, but the maximum number of cores in a single machine is around 16 to 32. This means that the number of cores does not scale, which is a problem when working with large data sets.
Another limitation is the amount of RAM that a single computer can handle. While it’s theoretically possible to increase RAM up to a Terrabyte (TB), this is not cost-efficient. Additionally, running extensive computations on a single machine can be risky, as a single error can require starting the entire job over again.
To overcome these limitations, it makes sense to move toward a distributed architecture. In a distributed system, a network of machines can work on several tasks in parallel. This is where Spark shines, as it is designed to run best on a computing cluster.
By leveraging a distributed architecture, Spark can parallelize workloads and optimize performance to handle massive data sets. With a network of machines working together, Spark can tackle complex computations in a robust and efficient way. In summary, the move to a distributed architecture is critical for overcoming the limitations of a local system and unlocking the full potential of Spark.
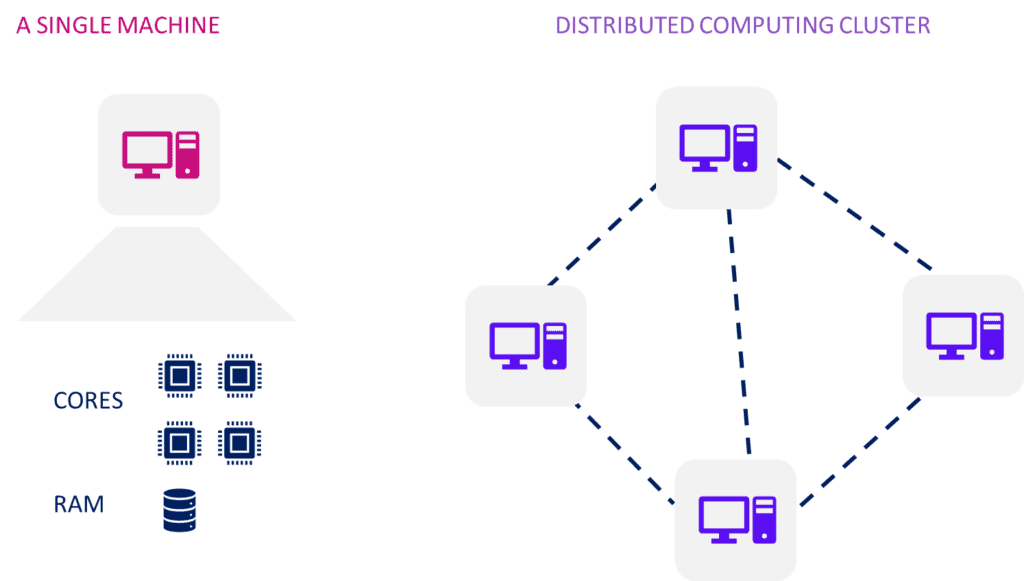
Cluster Computations
When it comes to Big Data, you want to parallelize as much as possible, as this can significantly reduce the time for processing workloads. If we speak about processing Terrabytes or Petabytes of data, we need to distribute the workload among a whole cluster of computers with hundreds or even thousands of cores. Here we run into another limitation: parallelization requires us to distribute tasks among cluster nodes, split the data, and store smaller chunks of data in each node.
Distributing the data across a cluster means transferring the data to the machines and either writing it to the hard disk or storing it in the Random Access Memory (RAM). Both choices have their pros and cons. While disk space is typically cheap, write operations are generally slow and thus expensive in terms of performance. Keeping the data in memory (RAM) is much faster. However, RAM is typically expensive. Compared to disk, there is less RAM space available to store the data, which requires breaking them up into a more significant number of smaller partitions.
Spark vs. Hadoop
Cluster computing frameworks existed long before Apache Spark. For example, Apache Hadoop was developed long before Apache Spark and used by many enterprises to process large workloads for some time.
A Matter of Persistence
Hadoop distributes the data across the nodes of a computing cluster. It then runs local calculations on the cluster nodes and collects the results. For this purpose, Hadoop relies on MapReduce, which persists the data to a distributed file system. An example is the Hadoop Distributed File System (HDFS). The advantage is that users don’t have to worry about task distributions or fault tolerance. Hadoop handles all of this under the hood.
The downside of MapReduce is that reads and writes take place on the local table storage, which is typically slow. However, modern analytics use cases often rely on the swift processing of large data volumes. Or in the case of machine learning and ad-hoc analytics, they require frequent iterative changes to the data. For these use cases, Spark provides a faster solution. Apache spark overcomes the costly persistence of data to the local table storage by keeping it in the RAM of the worker nodes. Spark will only spill data to the disk if the memory is full. Keeping data in memory can improve the performance of large workloads by an order of magnitude. The speed advantage can be as much as 100x.
When to Use Spark?
Spark’s in-memory approach offers a significant advantage if speed is crucial and the data fits into RAM. Especially when use cases require real-time analytics, Spark offers superior performance over Hadoop MapReduce. Such cases are, for example:
- Credit card fraud detection: Analysis of large volumes of transactions in real-time.
- Predictive Maintenance: Prediction of sensor data anomalies and potential machine failures with real-time analysis of IoT sensor data from machines and production equipment.
However, Spark is not always the best solution. For example, Hadoop may still be a great choice when processing speed is not critical. Sometimes the data may be too big for in-memory storage, even on a large computing cluster. In such cases, using Hadoop on a cluster optimized for this purpose can be more cost-effective. So, there are also cases where Hadoop offers advantages over Spark.
Spark Architecture
The secret to Spark’s performance is massive parallelization. Parallelization is achieved by decomposing a complex application into smaller jobs executed in parallel. Understanding this process requires looking at the distributed cluster upon which Spark will run its jobs.
A Spark cluster is a collection of virtual machines that allows us to run different workloads, including ETL and machine learning. Each computer typically has its RAM and multiple cores, allowing the system to speed up computations massively. Of course, cluster sizes may vary, but the general architecture remains generic.
A spark computing cluster has a driver node and several worker nodes. The driver node contains a driver program that sends tasks via a cluster manager to the worker nodes. Each worker node has an executer and holds only a fraction of the total data in its cache.
After job completion, the worker nodes send back the results, where the driver program aggregates them. This way, Spark avoids storing the data in the local disk storage and achieves swift execution.
Another advantage of this architecture is easy scaling. In a cluster, you can add machines to the network to increase computational power or remove them again when they are not needed.
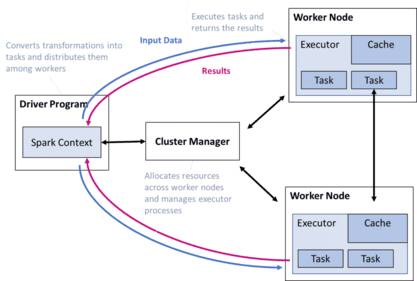
Source: based on https://spark.apache.org/docs/latest/cluster-overview.html
Spark Cluster Components
Clusters consist of a single driver node, multiple worker nodes, and several other key components:
Driver Node
The driver node has the role of an orchestrator in the computing cluster. It runs a java process that decomposes complex transformations (transformation and action) into the smallest units of work called tasks. It distributes them to the worker nodes for parallel execution as part of an execution plan (more on this topic later).
The driver program also launches the workers who read the input data from a distributed file system, decompose it into smaller partitions, and persist them in memory.
Spark has been designed to optimize task planning and execution automatically. In addition, the driver creates the Spark context (and Spark Session) that provides access to and deployment of cluster information, functions, and configurations.
Worker Node
Worker nodes are the entities that get the actual work done. Each worker hosts an executor on which the individual tasks run. Workers have a fixed number of executors that contain free slots for several tasks.
Workers also have their dedicated cache memory to store the data during processing. However, when the data is too big to store in memory, the executor will spill it onto the disk. The number of slots and ram available to store the data depends on the cluster configuration and its underlying hardware setup.
Cluster Manager
A cluster manager is the core process in Spark responsible for launching executors and managing the optimal distribution of tasks and data across a distributed computation cluster.
Spark supports different disk storage formats, including HDSF and Cassandra. The storage format is essential because it describes how Spark distributes the data across a network. For example, HDFS partitions the data into blocks of 128 MB and replicates these blocks three times – in this way, creating duplicate data to achieve fault tolerance. The fact that Spark can handle different storage formats makes it very flexible.
Executor
The executors are processes launched in coordination with the cluster manager. Once the executor is launched, it runs as long as the Spark application runs. They are responsible for executing tasks and returning the results to the driver. Each executor holds a fraction (a Spark Partition) of the data to be processed. The executor persists the data in the cache memory of the worker node unless the cache is full.
The Resilient Distributed Dataset (RDD)
The backbone of Apache Spark is the Resilient Distributed Dataset (RDD). The RDD is a distributed memory abstraction that provides functions for in-memory computations on large computing clusters.
Imagine you want to carry out a transformation on a set of historical temperature data. Running this on Spark will create an RDD. The RDD partitions the data and distributes the partitions to different worker nodes in the cluster.
The RDD has four main features:
- Partitioning: An RDD is a distributed collection of data elements partitioned across nodes in a cluster. Partitions are sets of records stored on one physical machine in the cluster.
- Resilience: RDDs achieve fault tolerance against failures of individual nodes through redundant data replication.
- Interface: The RDD provides a low-level API that allows performing transformations and tasks parallel to the data.
- Immutability: An RDD is an immutable replication of data, which means that changing the data requires creating a new RDD.
Since Spark 2.0, the Spark syntax orients towards the DataFrame object. As a result, you won’t interact with the RDD object anymore when writing code. However, the RDD is still how Spark stores data in memory and the RDD continues to excel under the hood.
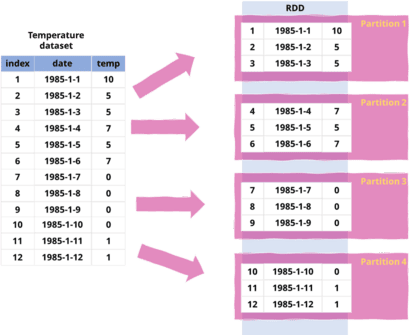
Performance Optimization
Processing data in distributed systems leads to an increased need for optimization. Spark already takes care of several optimizations, and new Spark versions constantly get better at improving performance. However, there are still cases where it is necessary to finetune things manually.
Essential concepts that allow Spark to distribute the computation cluster’s work efficiently are “lazy code evaluation” and “data shuffling.”
Lazy Code Evaluation
An essential pillar of Spark is the so-called lazy evaluation of transformations. The underlying premise is that Spark does not directly modify the data but only when the user calls an action.
Examples of transformations are join, select, groupBy, or partitionBy. When the user calls an “action,” the execution of transformations creates a new RDD. In contrast, actions collect results from the worker nodes and return them to the driver node. Examples of actions are “first,” “max”, “count”, or “collect”. For a complete list of transformations and actions, visit the Spark website.
sparkDF.withColumn('split_text', F.explode(F.split(F.lower('Word'), ''))) \
.filter("split_text != ''") \
.groupBy("split_text", "language")\
.pivot("split_text") \
.agg(count("split_text")
).drop("Word_new", "Word", "split_text").orderBy(["language"], ascending=[0, 0]).na.fill(0)
Spark can look at all transformations from a holistic perspective by lazily evaluating the code and carrying out optimizations. Before executing the transformation, Spark will generate an execution plan that considers all the operations and beneficially arranges them.
It is worth mentioning that Spark supports methods piling so that programmers can group multiple transformations without worrying about their order. The code example on the right illustrates this approach for the Python-specific API of Spark called PySpark.
Shuffle Operations
Shuffle is a technique for re-distributing data in a computation cluster. After a shuffle operation, the partitions are grouped differently among the cluster nodes. The illustration demonstrates this procedure.
An Expensive Operation
Shuffle typically requires copying data between executors and machines, thus making it an expensive operation. It requires data transfer between worker nodes, resulting in disk I/O and network-I/O. For this reason, we should avoid shuffle operations, if possible. However, several common transformations will invoke shuffle. Examples are join-operations, repartition-operations, and groupBy-operations. These operations will not work without shuffling the data because they often require a complete dataset.
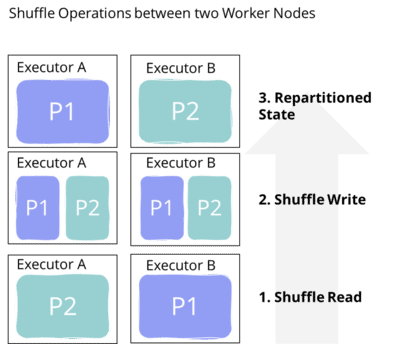
Avoiding Shuffle
Spark has several built-in features that help Spark avoid shuffling. However, some of these activities, such as scanning large datasets, will also cost performance. If the user already knows the scope and structure of the data, they should provide this information directly to Spark. Spark offers various parameters in its APIs for this purpose.
Avoiding shuffle operations may require manual optimization. A typical example is working with data sets that differ significantly in size (skewed data). For example, when doing join operations between a large and a small dataset, we can avoid shuffle operations by providing each worker node with a full copy of the smaller dataset. For this purpose, Spark has a broadcast function. The broadcast function copies a dataset to all worker nodes in the cluster, reducing the need to exchange partitions between nodes.
There are many more topics around optimizations. But since it’s a complex topic, I’ll cover it in a separate article.
Summary
This article has introduced Apache Spark, a modern framework for processing and analyzing Big Data on distributed systems. We have covered the basics of Spark’s architecture and how Spark distributes data and tasks among a computation cluster. Finally, we have looked at how Spark optimizes computations in distributed systems and why it is often necessary to improve things manually.
Now that you have a decent understanding of the essential concepts behind Spark, we can gather hands-on experience. The following article will work with PySpark, the Python-specific interface for Apache Spark. In this tutorial, we will process and analyze weather data using PySpark.
Analyzing Zurich Weather Data with PySpark
Thanks for reading, and if you have any questions, please let me know in the comments.
Sources and Further Reading
- Wenig Damji Das and Lee (2020) Learning Spark: Lightning-fast Data Analytics
- Chambers and Zaharu (2018) Spark: The Definitive Guide: Big data processing made simple
- Resilient Distributed Datasets: A Fault-Tolerant Abstraction for
- In-Memory Cluster Computing.pdf
- Andriy Burkov (2020) Machine Learning Engineering
- David Forsyth (2019) Applied Machine Learning Springer
The links above to Amazon are affiliate links. By buying through these links, you support the Relataly.com blog and help to cover the hosting costs. Using the links does not affect the price.
