

Recently, I’ve been exploring how to leverage intelligent agents to streamline the discovery and organization of real-world AI use cases from across the web. This experimentation led me to develop AIUseCaseHub.com, a platform that employs a multi-agent backend powered by Azure AI Foundry for finding and scraping cases online. In this article, I’d like to share some insights into how the agentic scraping process works. And I’ll provide some practical advice on building similar cloud-based projects through strategic use of Azure technologies and prompt engineering.
Intro: What is AIUseCaseHub.com?
AIUseCaseHub.com is a dynamic web app designed to curate and showcase AI use cases spanning various industries, countries, and sources from across the internet. I created this platform out of a recurring need—colleagues and partners regularly approach me with questions such as,
- “What interesting AI implementations are happening in finance?”,
- “Can you share examples of AI use cases in healthcare?”, or
- “Which Swiss customers have successfully implemented AI agents?”.
Recognizing the value of a consolidated resource, I started building agents to proactively monitor the web for AI implementations. The idea was to create an agentic flow that systematically searches the web for relevant cases and organizes the information.
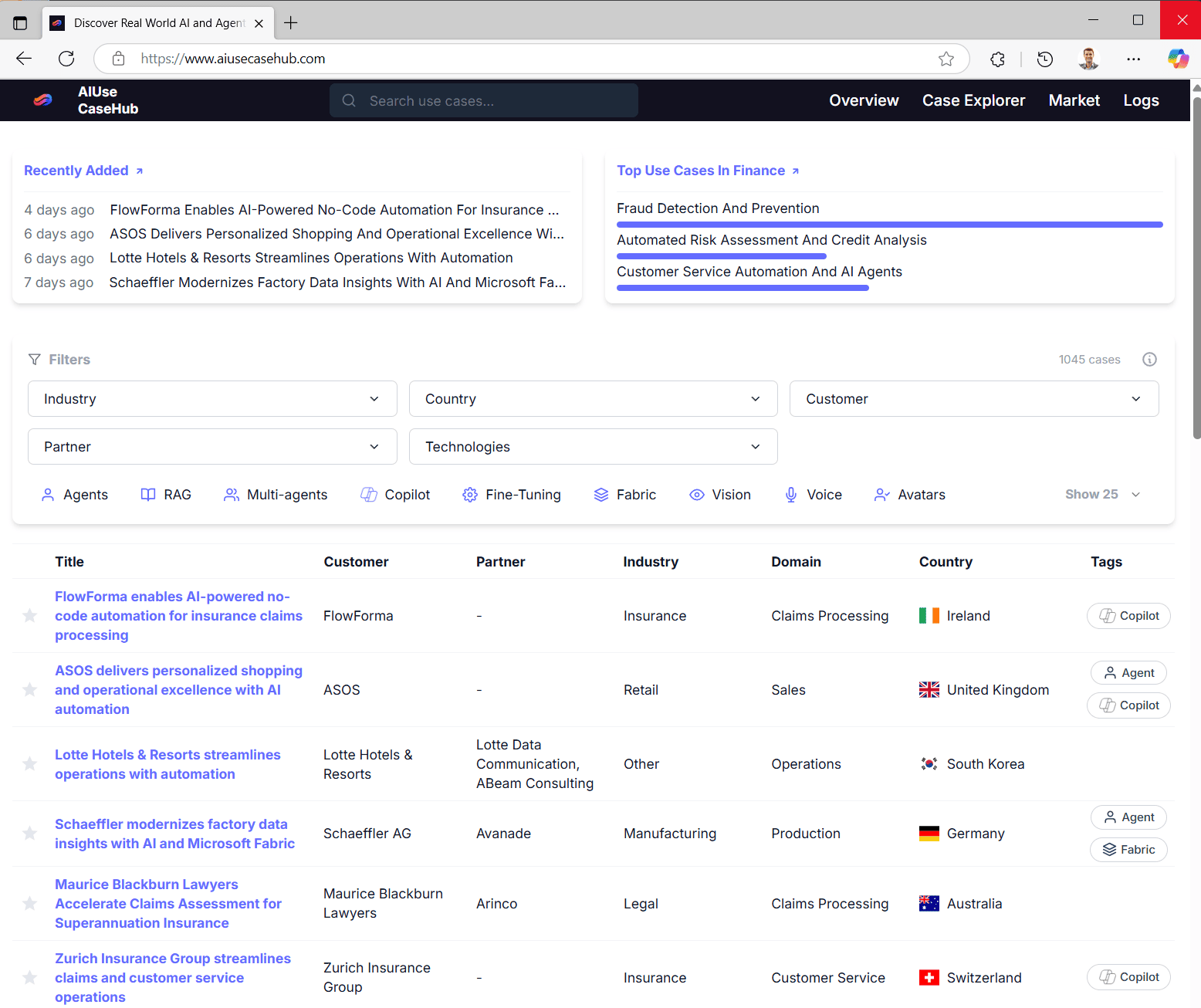

Once I recognized the significant value the collected use cases provided for my own work, I decided to share them more broadly by turning the internal database into a public web platform. Today, AIUseCaseHub.com is freely accessible to everyone, allowing anyone to easily explore and discover impactful AI implementations.
What are Agents?
Following the rise of Generative AI (GenAI), the next major shift revolves around AI agents. Essentially, these agents are large language models (LLMs) equipped with greater autonomy and the ability to actively use external tools. Sounds complicated? It’s really not. The trick is to empower an AI model to independently execute practical actions—like inserting data into databases, generating tickets, or sending emails—by deciding when and how to perform these tasks.
Integrating tools with LLMs isn’t entirely new; early approaches required meticulous parsing of structured outputs to initiate actions. Back when GPT-3 first gained popularity, getting an LLM to effectively utilize external tools was notably challenging. So where does the enthusiasm around agents come from? I believe it largely stems from advances in platforms like Microsoft’s Azure AI Agent Service that make building agents much easier than in the past.
Platforms such as Azure AI Foundry Agent Service now offer critical agent functionalities out-of-the-box—including robust conversation management (incl. memory and thread handling) and seamless tool integration—allowing developers to concentrate on instruction design and tool customization. This ease of use and lowered technical barriers truly defines the transformative power of today’s AI agents.
Modern agents adeptly break down intricate tasks into simpler subtasks, independently handling each step while maintaining a clear overall context. You may also have heard of standards like Model Context Protocol (MCP) or Agent-to-Agent (A2A). These are enhancing interoperability and provide a great long-term vision for agent-to-agent communication. However, i believe, the core breakthrough is the ease at which it is now possible to create and operate powerful agentic systems.
Agentic Scraping
Web scraping is the automated process of extracting information from websites—transforming unstructured web content into structured, usable data. It’s frequently used to gather valuable insights, track market trends, or consolidate information scattered across multiple sources online.
Traditionally, web scraping relies on manual scripting or rigid automation tools. These are typically designed for specific webpage layouts. The downside? These tools often break when even small webpage elements change. As a result, these tools require continuous adjustments to maintain data relevance and quality. Even minor alterations, such as changes in HTML elements or button placements, can disrupt conventional scraping workflows. This is why agents are particularly well-suited to web scraping. Their increased autonomy and adaptability allow them to adapt to changes and effectively handle complexity.
Agents can dynamically leverage multiple tools to flexibly respond to evolving conditions. They can execute web searches, open URLs and reason over structured and unstructured content scraped from the web. Their ability to try out alternative ways makes them more fault tolerant. They are thus providing a more robust and resilient alternative to traditional automation methods.
Let’s now take a look at the business challenge of web scraping and how agents can help.
The Business Challenge: Monitoring AI Use Cases Online
So why is it so hard to find and monitor AI use cases? Let me explain. I define an AI use case as a real world implementations of AI with a project-like nature. Such cases are scattered across the web and published by many sources. Cloud providers like Microsoft often publish them on industry-specific or event-specific sites. News outlets pick up these stories and republish them in different formats.
On top of that, customers, consulting firms, and technology partners share their own versions. This fragmented landscape makes it tricky to pinpoint all relevant pages. In addition, multiple sites might report the same use case in slightly different ways. This creates a high risk of duplicates. Furthermore, new cases appear on a daily basis, which demands for frequent updates.
Instead of tracking a few known sites manually, I tackled this challenge with an agent-driven approach. This approach makes use of the capability of an agent to use tools such as performing web search and opening URLs to extract content from the web directly. I also added techniques to boost data quality and reduce the chance of duplicates in the final dataset.
Agentic Scraping Architecture
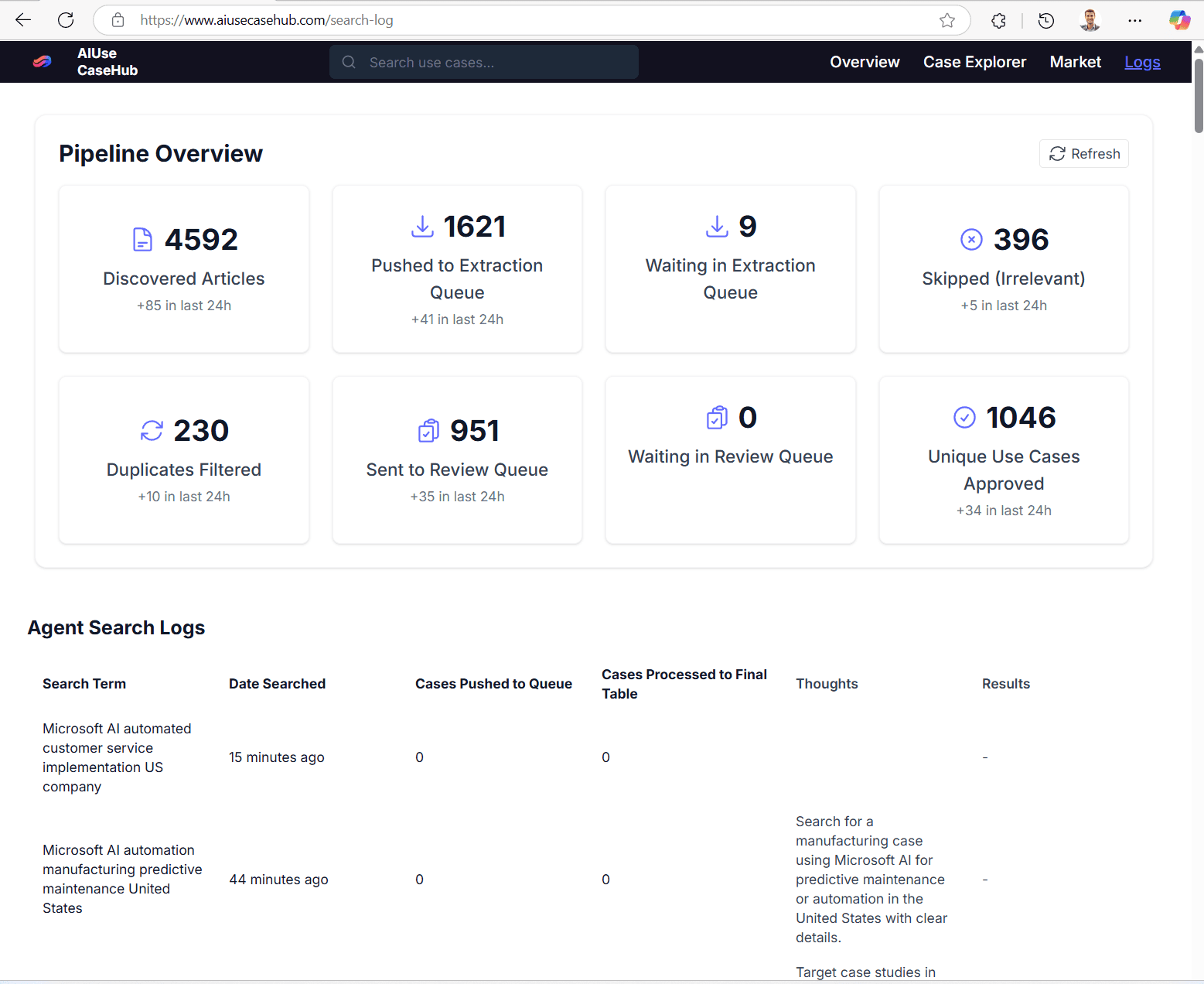
Returning to AIUseCaseHub.com, today multiple specialized agents work continuously—24 hours a day, seven days a week—to populate the platform with relevant AI use cases. The overall scraping architecture operates as a streamlined pipeline or queue, where numerous potential articles are assessed, but only the highest-quality entries reach the curated “gold” database.
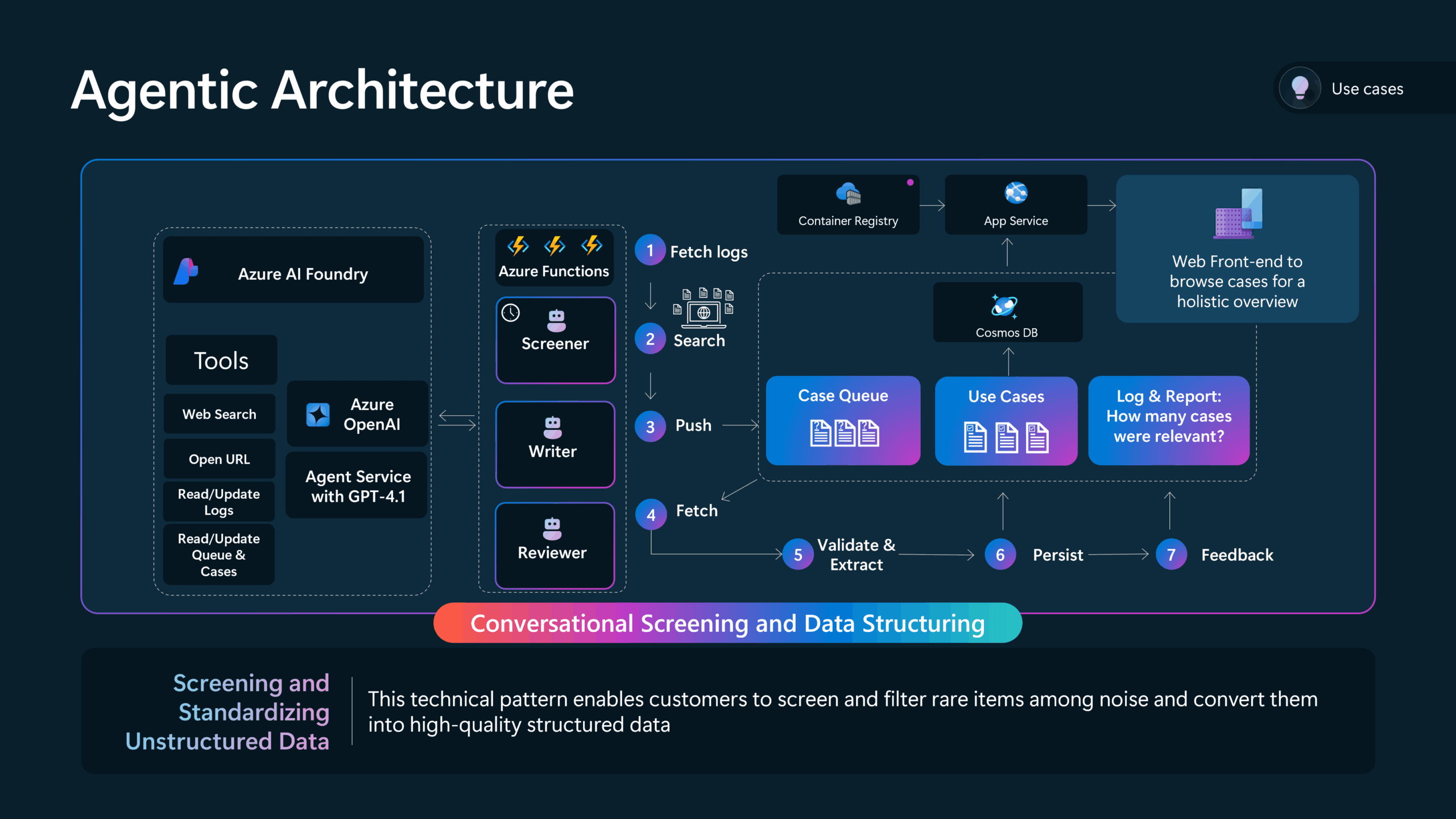
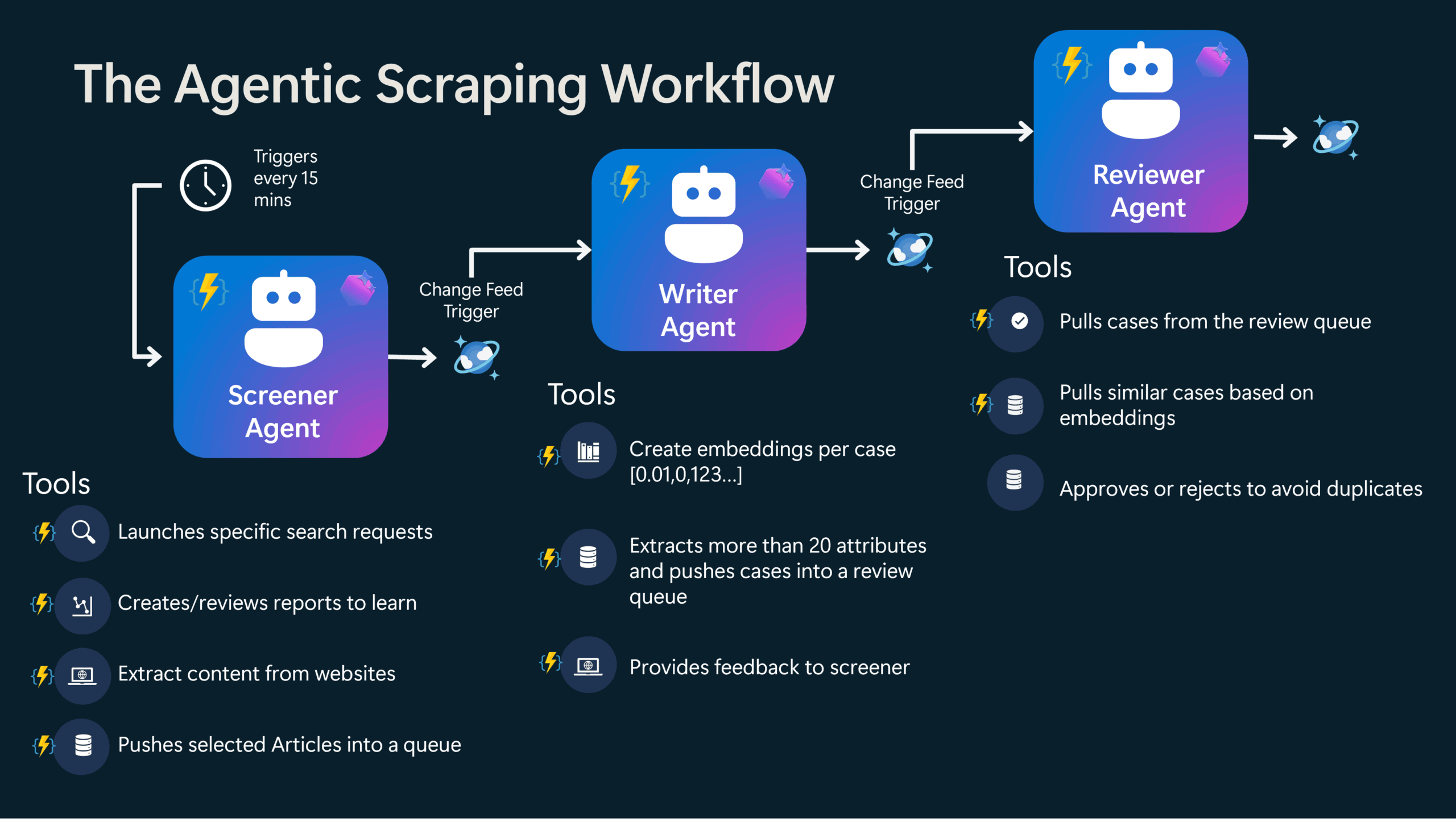
Four specialized agents collaboratively manage this workflow, each with clearly defined responsibilities:
Screener Agent
Searches the web for promising AI cases using traditional web search methods. It carefully screens results based on criteria such as real-world implementation, involvement of Microsoft technologies, clearly identified customers, demonstrated business impact or measurable outcomes, and a specific focus on AI, agents, or automation.
Writer Agent
Specializes in extracting structured information from selected web articles, utilizing multiple extraction methods. It meticulously captures over 30 different data points per case—including Industry, Country, Customer Name, and Partner Name. Due to its significant role in shaping overall data quality, the Writer Agent is particularly crucial within the workflow.
Reviewer Agent
Performs rigorous quality assurance checks and identifies potential duplicates. Additionally, the Reviewer Agent provides feedback directly into the search logs, creating a valuable feedback loop that continually refines the screening process.
(Social Media Agent)
Summarizes validated use cases from the gold database and publishes concise updates directly to my BlueSky Social account, ensuring broad visibility and engagement with a wider audience.
Agent Orchestration
For orchestrating the agents behind AIUseCaseHub.com, I rely on the Azure AI Agent Service, which simplifies agent creation by managing conversation memory and providing an intuitive Python SDK to seamlessly integrate various tools. Azure AI Agent Service supports multiple LLM models, including OpenAI’s GPT-4.1, GPT-4-mini, and GPT-4.1-nano. This flexibility allows me to strategically optimize costs by selecting the right model for each job. For example, I use smaller, less expensive models for simpler tasks such as web search while reserving powerful models for complex operations such as data extraction.
Agents still require a dedicated runtime environment for orchestration—this is the core system that invokes the LLMs, manages interactions with tools, and handles results. To fulfill this role efficiently, I host the orchestration logic on Azure Functions, a cost-effective, serverless computing platform. Moreover, most agent-specific tools are implemented as standalone Azure Functions exposing individual APIs, integrated via lightweight wrappers. This modular setup not only enables easy reuse of tools across different agents but also provides scalability and flexibility as the agent ecosystem grows.
Let’s now delve deeper into the specific tools utilized within this orchestration setup.
Tools Used in Agentic Scraping
The scraping workflow leverages a variety of specialized tools integrated into the agent orchestration to ensure efficient data collection, high-quality output, and robust content deduplication:
- Web Search:
Executes traditional web searches, returning approximately 30 fresh URLs per search. Only URLs not previously processed are retrieved, ensuring high data quality from the outset. The specific search terms are intelligently determined by the Screener Agent. - Content Scraper:
Attempts multiple approaches to reliably access URLs and extract textual content from articles, providing resilience against common scraping challenges. - Cosmos DB Integration:
Handles storage and retrieval operations in a structured, scalable manner using Azure Cosmos DB, enabling smooth data flow between agents and persistent data management. - Search Term Logging:
Logs all executed search terms, providing valuable insights into search effectiveness and ensuring continuous improvement of the agent’s search strategy. - Database Statistics:
Provides agents with real-time analytics from the database, such as industry and country distributions, helping guide decision-making for future searches and balancing the diversity of collected cases. - Feedback Tools:
Enables the Writer Agent to provide detailed feedback to the Screener Agent about irrelevant or duplicate cases, alongside explanations for each rejection. This feedback loop continuously refines the search and screening processes. - Data Quality Tools:
Ensures consistency and accuracy in critical fields, such as industry and customer names, by leveraging predefined taxonomies. The agents proactively query existing database entries to prevent inconsistencies or variations (e.g., avoiding multiple variants like “Zurich Insurance AG,” “Zurich Insurance,” and “Zurich Germany”). - Deduplication Checks:
Generates embeddings for every new use case entering the queue, enabling efficient detection of similar cases. If cases exceed a similarity threshold, indicating potential duplication, they’re merged by linking additional sources to the existing entry rather than creating duplicates. These embeddings also support advanced exploration features, such as a visual 2D explorer of use cases and recommendations for related cases.
Single Agent vs Multi-Agent Workflows
It’s common for agentic projects to begin with a single, general-purpose agent, which is then divided into multiple specialized agents as complexity grows. This was exactly the case when I started building the agentic scraping pipeline for AIUseCaseHub.com. Initially, I had a single agent handling all tools and tasks. However, as I added more features to improve performance and accuracy, this all-in-one setup became increasingly unwieldy—especially for the data extraction step, which requires detailed instructions and careful handling.
At that point, it made sense to split the original agent into two specialized roles: one agent dedicated to screening for relevant cases and another focused entirely on writing and structuring the extracted information. This separation significantly improved both results and maintainability.
Yet, some tasks related to reviewing and ensuring data quality didn’t quite fit neatly into either of these two agents. To handle these checks more effectively, I added a separate Reviewer Agent. This three-agent setup proves to be a solid fit for now: it strikes a good balance between leveraging agents for process automation and keeping the overall workflow streamlined and manageable, with minimal unnecessary back-and-forth.
Multi-Agent Flow
There is currently no master agent orchestrating the entire process. Instead, each agent handles a specific step in the workflow. Agents don’t communicate with each other directly but coordinate indirectly through Azure Cosmos DB—by reading, writing, and retrieving records.
The Screener Agent runs on a 30-minute schedule. It can launch multiple searches in one run until it finds relevant cases. Once the Screener has added a potential case to the database, the Writer Agent and Reviewer Agent take over. They are triggered automatically by Cosmos DB’s change feed monitoring, which works seamlessly with Azure Functions. When a new record appears in the initial stage container, the Writer Agent processes it. The same mechanism triggers the Reviewer Agent for the next step.
The scraping pipeline is not error-free. Therefore, I added retry and repeat operations to handle failed steps, making the entire process more robust. This design is optimized for Azure Functions, which have a maximum execution time of five minutes per run. Keeping each step small and stateless avoids the need for complex async logic and makes testing and maintenance much easier.
A Word on the Cost of Running Scraping Agents
Using agents is generally not inexpensive. Higher-quality models typically produce fewer errors and complete tasks faster, but this comes with increased cost. For steps where mistakes could have a significant negative impact, it’s worthwhile to invest in stronger models to maintain accuracy and reliability.
Splitting the workflow into multiple agents instead of relying on a single, all-purpose agent helps optimize cost and performance by allowing different model sizes for different tasks. For example, in my setup, the Writer and Reviewer Agents run on the more capable but more expensive GPT-4.1. On the other hand, the token-intensive first step—screening for potential cases—uses the lighter and more cost-effective GPT-4.1-mini.
Naturally, more agent runs directly translate to higher costs, so it’s crucial to minimize searches that yield no valuable results. Additionally, over time, scraping efficiency tends to decline slightly as easily discoverable cases are exhausted. This means, it gets progressively harder for the agents to find fresh, unique examples.
Learning Agents
LLMs like GPT-4.1, by design, can’t truly learn autonomously—they can only adapt their behavior within each session using updated information in their context window. To make my scraping agents more effective, I implemented a pseudo-learning mechanism to guide the Screener Agent toward finding more diverse and relevant cases.
Without this, the Screener Agent often repeats the same search terms, reducing the chances of uncovering new content. This is essentially a variance challenge: ensuring the agent continuously explores untapped areas of the web rather than circling familiar ground.
To address this, before defining and executing each new search, the Screener Agent calls a custom tool that provides a performance report. This report includes two key insights:
- Search Log: A summary of the last 30 search terms used, along with the number of valid cases each produced that successfully made it into the final gold table.
- Database Statistics: A snapshot of the current distribution of use cases in the gold table, broken down by industry and by country.
This approach introduces a system of dynamic feedback. It equips the agent to vary its search strategy intelligently, improving both efficiency and discovery quality.
Example performance report provided to the Screener Agent:
(JSON or tabular sample can follow here)
{
"recent_searches": "SearchTerm # CaseHits # DateSearchedUTC\n----------------------------------------------------------------------\nMicrosoft Azure AI in Telemedicine Optimization for Teladoc US # 0 # 2025-05-01T20:07:50\nMicrosoft Power Platform in Customer Service Automation for Unilever UK # 0 # 2025-05-01T20:07:47\nMicrosoft Azure AI Supply Chain Optimization for Nestle Switzerland # 0 # 2025-05-01T20:07:45\nMicrosoft AI in Fraud Detection Banking for JPMorgan Chase US # 0 # 2025-05-01T20:07:43 ...",
"statistics": {
"industry_stats": {
"Healthcare": 133,
"Retail": 57,
"Finance": 99,
"Tech & Comms": 87,
"Manufacturing": 135,
"Automotive": 23,
"Legal": 49,
"Education": 23,
"Pharma": 24,
"Logistics": 33,
"Insurance": 132,
"Energy & Utilities": 45,
"Consumer & Food": 35,
"Other": 19,
"Agriculture": 37,
"Real Estate": 21,
"Professional Services": 56,
"Public Sector": 39
},
"country_stats": {
"US": 307,
"CH": 91,
"DK": 13,
...
}
}
}This mechanism of providing feedback to the screener agent has proven crucial for maintaining high search performance. It ensures sufficient variety, continuously uncovering fresh use cases from across the web, spanning different industries and countries. You can validate that the feedback process has an impact by viewing the agent thoughts in the log files (as shown below). There you will frequently see comments such as “I focus on this underrepresented field”, or “I focus on this and that field where i had frequent hits”.
Summary
Building AIUseCaseHub.com has been an eye-opening journey in using modern agentic workflows with Microsoft Azure’s AI Agent Service. I combined a robust multi-agent setup, serverless orchestration on Azure Functions, and tailored tools for search, scraping, and deduplication. The result is a system that runs non-stop, finding, refining, and sharing real-world AI use cases—saving countless hours and surfacing insights that would otherwise stay buried.
For me personally, this project has shown how easy and powerful agentic design has become. What once needed complex engineering now works with cloud-native services and smart prompt design. If you’re looking to automate content discovery, organize domain knowledge, or test agent-driven ideas, I hope this deep dive sparks ideas and gives you a head start.
What is also worth mentioning, a lot of the code i wrote for the front-end and some parts of the backend were vibe-coded using GitHub Copilot. It’s extremely powerful to demonstrate that something works in a short amount of time. But the experience of vibe coding this app deserves a separate article on its own.
The journey doesn’t stop here. AIUseCaseHub will keep growing to cover more technologies and industries. Explore it to see how AI transforms businesses worldwide—and stay tuned for what’s next.
Right now, the hub only features projects using Microsoft technology. But I plan to include use cases from other cloud providers soon.
Sources and Useful Links
- AIUseCaseHub.com — Explore the live use case platform.
- BlueSky Social — Where the Social Media Agent publishes summarized use cases.
- Microsoft Azure AI Agent Service (Preview) — Overview, architecture, and quickstart.
- Azure Functions Documentation — Learn how to run serverless orchestration.
- Azure Cosmos DB Documentation — Guide for storing structured data and using change feed.
- Azure AI Foundry — Foundation for building and managing AI applications.
