

Twitter is a rich source of data that can be used to understand current and future trends. Because tweets often include hashtags, they can be easily linked to specific contexts such as political discussions or financial instruments. This makes Twitter a valuable tool for collecting and analyzing data. In this article, we’ll demonstrate how to use Python to access Twitter data via the Twitter API v2. We’ll show how to extract tweets, process them, and use them to gain insights and make predictions. Whether you’re a data scientist, a business analyst, or a social media enthusiast, this tutorial will provide you with the tools you need to work with Twitter data in Python.
This article shows two specific cases:
- Example A: Streaming Tweets and Storing the Data in a DataFrame
- Example B: Streaming Images for a specific channel and storing them in a local directory
If you are new to APIs, consider first familiarizing yourself with the basics of REST APIs.
The rest of this article is structured as follows: First, we’ll look at how to sign up to use the Twitter API and obtain an authentication token. We will then look at the object model of Twitter and use the security token in our requests to the Twitter API. Then we will turn to the two examples, A & B.
Basics of the Twitter API
Twitter data has a variety of applications. For example, we can analyze tweets to discover trends or evaluate sentiment on a topic. Furthermore, images embedded in tweets and hashtags can train image recognition models or validate them. Thus, knowing how to obtain data via the Twitter API can be helpful if you are doing data science.
API Versions
Twitter provides two different API versions: The two versions have their documentation and are incompatible. While the API v1.1 is still more established, Twitter API v2 offers more options for fetching data from Twitter. For example, it allows tailoring the fields given back with the response, which can be helpful if the goal is to minimize traffic. The Twitter API v2 is currently in early access mode, but it will sooner or later become the new standard API in the market. Therefore, I decided to base this tutorial on the newer v2-version.
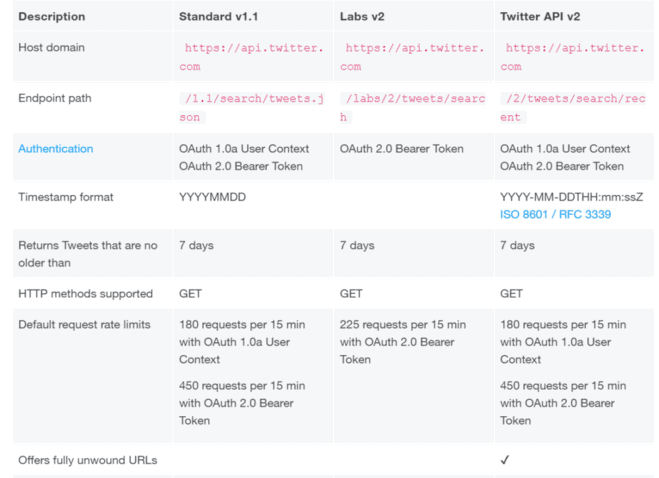
Twitter API Documentation
When working with the Twitter API v2, it is vital to understand the Twitter object model. The tweet object acts as the parent of four subobjects: according to the API documentation, the basic building block of Twitter is the Tweet object. It has various fields attached, such as the tweet text, created_at, and tweet id. The Twitter API documentation provides a complete list of these root-level fields. The standard API response does not include most of the areas. If we want to retrieve additional fields, we need to specify these fields in the request rules.
Each object, in turn, has multiple fields for which we specify which fields to return in the rule, as with the Tweet Object. This article uses the tweet object and the media object, which contains all the media (e.g., images or videos) that tweets can have attached.
Functioning of the Recent Search Endpoint
In this tutorial, we will be working with the Twitter Recent Search Endpoint. There are also other API endpoints, but covering all of them would go beyond the scope of this article. One notable feature of the Recent Search endpoint is that we can’t retrieve the data directly using GET requests but first have to send a POST request to the API specifying which information we want to fetch. To change these rules, we first have to delete them with a POST request and then pass the new ruleset to the API with another POST request. This procedure may sound complicated, but it gives the user more control over the API.
Different API Models
We can use the “Recent Search Endpoint” in batch and streaming modes. In batch mode, the endpoint returns a list of tweets once. If the stream option is enabled, the API returns a continuous flow of individual tweets, plus any new tweets as they are published to Twitter. In this way, we can stream and process tweets in (almost) real-time. In this tutorial, we will work with the streaming option enabled.
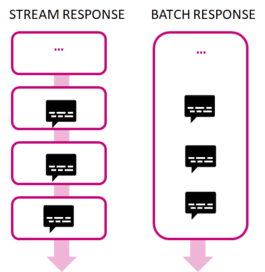
Filters
We can limit the tweets and fields that the API includes in the response by specifying parameters. For example, we can let the API know that we want to retrieve tweets with specific keywords or in a certain period or only those tweets with images attached. The API documentation provides a list of all filter parameters.
Twitter Search-API Python Examples
To stream tweets from Twitter, you will need to use the Twitter API. The API allows developers to access Twitter’s data and functionality, including the ability to stream real-time tweets. In order to stream tweets, you will need to sign up for a Twitter developer account and obtain the necessary credentials, such as a consumer key and access token. Once you have these credentials, you can use them to authenticate your API requests and access the streaming endpoint for tweets.
Setup a Twitter Developer Account
Using the Twitter API requires you to have your own Twitter developer account. If you don’t have an account yet, you need to create it on the Twitter developer page. As of Jan 2021, the standard developer account is free and comes with a limit of 500.000 tweets that you can fetch per month.
After logging into your developer account, go to the developer dashboard page and create a new project with a name of your choice. Once you have created a project, it will be shown in the “projects dashboard,” along with an overview of your monthly tweet usage. In the next section, you will retrieve your API key from the project.
Obtaining your Twitter API Security Key
The Twitter API accepts our requests only if we provide a personal Bearer token for authentication. Each project has its Bearer token. You can find the bearer token in the Developer Portal under the Authentication Token section. Store the token somewhere in between. In the next step, we will store it in a secure location.
Storing and Loading API Tokens
The Twitter API requires the user to authenticate during use by providing a secret token. It is best not to store these keys in your project but to put them separately in a safe place. In a production environment, you would, of course, want to decrypt the keys. However, it should be sufficient to store the key in a separate python file for our test case.
Create a new Python file called “twitter_secrets.py” and fill in the following code. Then replace the Bearer_Key with the key you retrieved from the Twitter Developer portal in the previous step.
In the following, create a Python file called “twitter_secrets.py” and fill in the code below:
"""Replace the values below with your own Twitter API Tokens"""
# Twitter Bearer Token
BEARER_KEY = "your own BEARER KEY"
class TwitterSecrets:
"""Class that holds Twitter Secrets"""
def __init__(self):
self.BEARER_KEY = BEARER_KEY
# Tests if keys are present
for key, secret in self.__dict__.items():
assert secret != "", f"Please provide a valid secret for: {key}"
twitter_secrets = TwitterSecrets()Then replace the Bearer_Key with the key you retrieved from the Twitter Developer portal in the previous step.
The twitter_screts.py has to go to the package library of your python environment. If you use anaconda under Windows, the path is typically: <user>\anaconda3\Lib. Once you have placed the file in your python library, you can import it into your python project and use the bearer token from the import, as shown below:
# imports the twitter_secrets python file in which we store the twitter API keys from twitter_secrets import twitter_secrets as ts bearer_token = ts.BEARER_TOKEN
Prerequisites
Before starting the coding part, make sure that you have set up your Python 3 environment and required packages. If you don’t have an environment set up yet, you can follow this tutorial to set up the Anaconda environment.
Also, make sure you install all required packages. In this tutorial, we will be working with the following standard packages:
You can install packages using console commands:
- pip install <package name>
- conda install <package name> (if you are using the anaconda packet manager)
Example A: Streaming Tweets via the Twitter Recent Search Endpoint
In the first use case, we will first define some simple filter rules and then request tweets from the API based on these rules. As a response, the API returns a stream of tweets which we will process further. We store the text from the tweets in a DataFrame and further tweet information.
We won’t detail all the code components, but we will go through the most important functions with inline code. The code is available on the GitHub repository.
Step #1: Define Functions to Interact with the Twitter API
We begin by defining functions to interact with the Twitter API.
import requests
import json
import pandas as pd
# imports the twitter_secrets python file in which we store the twitter API keys
from twitter_secrets import twitter_secrets as ts
# a function that provides a bearer token to the API
def create_headers(bearer_token):
headers = {"Authorization": "Bearer {}".format(bearer_token)}
return headers
# this function defines the rules on what tweets to pull
def set_rules(headers, delete, bearer_token, rules):
payload = {"add": rules}
response = requests.post(
"https://api.twitter.com/2/tweets/search/stream/rules",
headers=headers,
json=payload,
)
if response.status_code != 201:
raise Exception(
"Cannot add rules (HTTP {}): {}".format(response.status_code, response.text)
)
print(json.dumps(response.json()))
# this function requests the current rules in place
def get_rules(headers, bearer_token):
response = requests.get(
"https://api.twitter.com/2/tweets/search/stream/rules", headers=headers
)
if response.status_code != 200:
raise Exception(
"Cannot get rules (HTTP {}): {}".format(response.status_code, response.text)
)
print(json.dumps(response.json()))
return response.json()
# this function resets all rules
def delete_all_rules(headers, bearer_token, rules):
if rules is None or "data" not in rules:
return None
ids = list(map(lambda rule: rule["id"], rules["data"]))
payload = {"delete": {"ids": ids}}
response = requests.post(
"https://api.twitter.com/2/tweets/search/stream/rules",
headers=headers,
json=payload
)
if response.status_code != 200:
raise Exception(
"Cannot delete rules (HTTP {}): {}".format(
response.status_code, response.text
)
)
print(json.dumps(response.json()))
# this function starts the stream
def get_stream(headers, set, bearer_token, expansions, fields, save_to_disk, save_path):
data = []
response = requests.get(
"https://api.twitter.com/2/tweets/search/stream" + expansions + fields, headers=headers, stream=True,
)
print(response.status_code)
if response.status_code != 200:
raise Exception(
"Cannot get stream (HTTP {}): {}".format(
response.status_code, response.text
)
)
i = 0
for response_line in response.iter_lines():
i += 1
if i == max_results:
break
else:
json_response = json.loads(response_line)
#print(json.dumps(json_response, indent=4, sort_keys=True))
try:
save_tweets(json_response)
if save_to_disk == True:
save_media_to_disk(json_response, save_path)
except (json.JSONDecodeError, KeyError) as err:
# In case the JSON fails to decode, we skip this tweet
print(f"{i}/{max_results}: ERROR: encountered a problem with a line of data... \n")
continue
# this function saves a tweet to the SQLite DB
def save_tweets(tweet):
print(json.dumps(tweet, indent=4, sort_keys=True))
data = tweet['data']
public_metrics = data['public_metrics']
tweet_list.append([data['id'], data['author_id'], data['created_at'], data['text'], public_metrics['like_count']])
Step #2: Subscribe to the Tweet Streaming Service
Next, we subscribe to a stream of tweets. Once you have subscribed to the stream, you can process the received tweets as needed, such as by filtering or storing them for further analysis.
In this example, we will simply save the data to disk and append it to a text file. Tweets may have media files attached. If you also like to save these images to disk, you can set the save_media_to_disk variable to “True.”
# the max number of tweets that will be returned
max_results = 20
# save to disk
save_media_to_disk = False
save_path = ""
# You can adjust the rules if needed
search_rules = [
{"value": "dog has:images", "tag": "dog pictures", "lang": "en"},
{"value": "cat has:images -grumpy", "tag": "cat pictures", "lang": "en"},
]
tweet_fields = "?tweet.fields=attachments,author_id,created_at,public_metrics"
expansions = ""
tweet_list = []
bearer_token = ts.BEARER_TOKEN
headers = create_headers(bearer_token)
rules = get_rules(headers, bearer_token)
delete = delete_all_rules(headers, bearer_token, rules)
set = set_rules(headers, delete, bearer_token, search_rules)
get_stream(headers, set, bearer_token, expansions, tweet_fields, save_media_to_disk, save_path)
df = pd.DataFrame (tweet_list, columns = ['tweetid', 'author_id' , 'created_at', 'text', 'like_count'])
dfExample B: Streaming Images from Twitter to Disk
The second use case is streaming image data from Twitter. Twitter images are useful in various machine learning use cases, e.g., training models for image recognition and classification.
To be able to use the images later, we save them directly to our local drive. To do this, we reuse several functions from the first use case. We add some functions for creating the folder structure in which we then store the images. You can also find the code for this example on Github. The code is available on the GitHub repository.
Step #1: Define Functions to Interact with the Twitter API
import requests
import json
import pandas as pd
import urllib
import os
from os import path
from datetime import datetime as dt
# imports the twitter_secrets python file in which we store the twitter API keys
from twitter_secrets import twitter_secrets as ts
def create_headers(bearer_token):
headers = {"Authorization": "Bearer {}".format(bearer_token)}
return headers
def set_rules(headers, delete, bearer_token, rules):
payload = {"add": rules}
response = requests.post(
"https://api.twitter.com/2/tweets/search/stream/rules",
headers=headers,
json=payload,
)
if response.status_code != 201:
raise Exception(
"Cannot add rules (HTTP {}): {}".format(response.status_code, response.text)
)
print(json.dumps(response.json()))
def get_rules(headers, bearer_token):
response = requests.get(
"https://api.twitter.com/2/tweets/search/stream/rules", headers=headers
)
if response.status_code != 200:
raise Exception(
"Cannot get rules (HTTP {}): {}".format(response.status_code, response.text)
)
print(json.dumps(response.json()))
return response.json()
def delete_all_rules(headers, bearer_token, rules):
if rules is None or "data" not in rules:
return None
ids = list(map(lambda rule: rule["id"], rules["data"]))
payload = {"delete": {"ids": ids}}
response = requests.post(
"https://api.twitter.com/2/tweets/search/stream/rules",
headers=headers,
json=payload
)
if response.status_code != 200:
raise Exception(
"Cannot delete rules (HTTP {}): {}".format(
response.status_code, response.text
)
)
print(json.dumps(response.json()))
def get_stream(headers, set, bearer_token, expansions, fields, save_to_disk, save_path):
data = []
response = requests.get(
"https://api.twitter.com/2/tweets/search/stream" + expansions + fields, headers=headers, stream=True,
)
print(response.status_code)
if response.status_code != 200:
raise Exception(
"Cannot get stream (HTTP {}): {}".format(
response.status_code, response.text
)
)
i = 0
for response_line in response.iter_lines():
i += 1
if i == max_results:
break
else:
json_response = json.loads(response_line)
#print(json.dumps(json_response, indent=4, sort_keys=True))
try:
save_tweets(json_response)
if save_to_disk == True:
save_media_to_disk(json_response, save_path)
except (json.JSONDecodeError, KeyError) as err:
# In case the JSON fails to decode, we skip this tweet
print(f"{i}/{max_results}: ERROR: encountered a problem with a line of data... \n")
continue
def save_tweets(tweet):
#print(json.dumps(tweet, indent=4, sort_keys=True))
data = tweet['data']
includes = tweet['includes']
media = includes['media']
for line in media:
tweet_list.append([data['id'], line['url']])
def save_media_to_disk(tweet, save_path):
data = tweet['data']
#print(json.dumps(data, indent=4, sort_keys=True))
includes = tweet['includes']
media = includes['media']
for line in media:
media_url = line['url']
media_key = line['media_key']
pic = urllib.request.urlopen(media_url)
file_path = save_path + "/" + media_key + ".jpg"
try:
with open(file_path, 'wb') as localFile:
localFile.write(pic.read())
tweet_list.append(media_key, media_url)
except Exception as e:
print('exception when saving media url ' + media_url + ' to path: ' + file_path)
if path.exists(file_path):
print("path exists")
def createDir(save_path):
try:
os.makedirs(save_path)
except OSError:
print ("Creation of the directory %s failed" % save_path)
if path.exists(savepath):
print("file already exists")
else:
print ("Successfully created the directory %s " % save_path)Step #2: Define the Folder Structure to Store the Images
We want to store images contained in tweets on disk. To find these images again afterward, we create a new directory for each run.
# save to disk
save_to_disk = True
if save_to_disk == True:
# detect the current working directory and print it
base_path = os.getcwd()
print ("The current working directory is %s" % base_path)
img_dir = '/twitter/downloaded_media/'
# the write path in which the data will be stored. If it does not yet exist, it will be created
now = dt.now()
dt_string = now.strftime("%d%m%Y-%H%M%S")# ddmmYY-HMS
save_path = base_path + img_dir + dt_string
createDir(save_path)Step #3: Subscribe to the Tweet Streaming Service
Finally, we call the Twitter API and subscribe to the Streaming Service. We store the tweet id and the preview image URL in a DataFrame (df).
# the max number of tweets that will be returned
max_results = 10
# You can adjust the rules if needed
search_rules = [
{"value": "dog has:images", "tag": "dog pictures", "lang": "en"},
]
media_fields = "&media.fields=duration_ms,height,media_key,preview_image_url,public_metrics,type,url,width"
expansions = "?expansions=attachments.media_keys"
tweet_list = []
bearer_token = ts.BEARER_TOKEN
headers = create_headers(bearer_token)
rules = get_rules(headers, bearer_token)
delete = delete_all_rules(headers, bearer_token, rules)
set = set_rules(headers, delete, bearer_token, search_rules)
get_stream(headers, set, bearer_token, expansions, media_fields, save_to_disk, save_path)
df = pd.DataFrame (tweet_list, columns = ['tweetid', 'preview_image_url'])
dfSummary
In this tutorial, you learned how to stream and process Twitter data in near real-time using the Twitter API v2 with two use cases. The first use case has shown requesting tweet text and how to store it in a DataFrame. In the second case, we have streamed images and saved them to a local directory. There are many more ways to interact with the Twitter API, but it’s already possible to implement some exciting projects based on these two cases.
If you liked this post, leave a comment. And if you want to learn more about using the Twitter API with Python, consider checking out my other articles:
Sources and Further Reading
- https://developer.twitter.com/en/docs/twitter-api A part of the presented Python code stems from the Twitter API documentation and has been modified to fit the purpose of this article.

I am trying to stream tweets via the API v2 using the user object and would like to store the text in a SQL database.
Could anyone please help me with this as my code is not working?
import requests
import json
import pandas as pd
# imports the twitter_secrets python file in which we store the twitter API keys
# place the twitter_secrets file under /anaconda3/Lib
from twitter_secrets import twitter_secrets as ts
# puts the bearer token in the request header
def create_headers(bearer_token):
headers = {“Authorization”: “Bearer {}”.format(bearer_token)}
return headers
# sets the rules on which tweets to retrieve
def set_rules(headers, delete, bearer_token, rules):
payload = {“add”: rules}
response = requests.post(
“https://api.twitter.com/2/tweets/search/stream/rules”,
headers=headers,
json=payload,
)
if response.status_code != 201:
raise Exception(
“Cannot add rules (HTTP {}): {}”.format(response.status_code, response.text)
)
print(json.dumps(response.json()))
# retrieves the current set of rules from the API
def get_rules(headers, bearer_token):
response = requests.get(
“https://api.twitter.com/2/tweets/search/stream/rules”, headers=headers
)
if response.status_code != 200:
raise Exception(
“Cannot get rules (HTTP {}): {}”.format(response.status_code, response.text)
)
print(json.dumps(response.json()))
return response.json()
# tells the API to delete our current rule configuration
def delete_all_rules(headers, bearer_token, rules):
if rules is None or “data” not in rules:
return None
ids = list(map(lambda rule: rule[“id”], rules[“data”]))
payload = {“delete”: {“ids”: ids}}
response = requests.post(
“https://api.twitter.com/2/tweets/search/stream/rules”,
headers=headers,
json=payload
)
if response.status_code != 200:
raise Exception(
“Cannot delete rules (HTTP {}): {}”.format(
response.status_code, response.text
)
)
print(json.dumps(response.json()))
# starts the stream, iterates through the lines of the response and for each line calls the save_tweets function
def get_stream(headers, set, bearer_token, expansions, fields):
data = []
response = requests.get(
“https://api.twitter.com/2/tweets/search/stream” + expansions + fields, headers=headers, stream=True,
)
print(response.status_code)
if response.status_code != 200:
raise Exception(
“Cannot get stream (HTTP {}): {}”.format(
response.status_code, response.text
)
)
i = 0
for response_line in response.iter_lines():
i += 1
if i == max_results:
break
else:
json_response = json.loads(response_line)
# print(json.dumps(json_response, indent=4, sort_keys=True))
try:
save_tweets(json_response)
except (json.JSONDecodeError, KeyError) as err:
# In case the JSON fails to decode, we skip this tweet
print(f”{i}/{max_results}: ERROR: encountered a problem with a line of data… \n”)
continue
# appends information from tweets to a dataframe
def save_tweets(tweet):
print(json.dumps(tweet, indent=4, sort_keys=True))
data = tweet[‘data’]
includes = tweet[‘includes’]
user = includes[‘user’]
tweet_list.append([data[‘id’], data[‘author_id’], data[‘created_at’], data[‘text’], user[‘username’]])
# the max number of tweets that will be returned
max_results = 20
# You can adjust the rules if needed
search_rules = [
{
“value”: “-is:retweet (from:NWSNHC OR from:NHC_Atlantic OR from:NWSHouston OR from:NWSSanAntonio OR from:USGS_TexasRain OR from:USGS_TexasFlood OR from:JeffLindner1)”
}
]
# defines the fields which we want to retrieve
tweet_fields = “?tweet.fields=attachments,author_id,created_at,conversation_id”
user_fields = “&user.fields=username”
# we only retrieve the tweet object, but if we wanted to retrieve other objects (e.g., media), we would add them to the expansions string
expansions = “?expansions=author_id”
tweet_list = []
bearer_token = ts.BEARER_TOKEN
headers = create_headers(bearer_token)
rules = get_rules(headers, bearer_token)
delete = delete_all_rules(headers, bearer_token, rules)
set = set_rules(headers, delete, bearer_token, search_rules)
get_stream(headers, set, bearer_token, expansions, tweet_fields)
df = pd.DataFrame (tweet_list, columns = [‘tweetid’, ‘author_id’ , ‘created_at’, ‘text’, ‘conversation_id’, ‘username’])
df.to_csv(‘tweets.csv’)