Building a Virtual AI Assistant (aka Copilot) for Your Software Application: Harnessing the Power of LLMs like ChatGPT

Key takeaways
- A modern AI copilot decomposes into six parts: conversational UI, LLM, knowledge store, conversation control logic, application API, and cache.
- Users never talk to the LLM directly; control logic sits between them and enriches prompts with knowledge-store or search-API data (RAG).
- Token limits force you to ground the assistant via a knowledge store (e.g. a vector database with similarity search) rather than packing everything into one prompt.
- Mix models by task: cheaper models for intent recognition, a stronger model for the complex final prompt that builds the API call.
- The application API turns language into action; start with a few intents and a feedback mechanism, and expand over time while keeping the user in control.
Welcome to the dawn of a new era in digital interaction! With the advent of Generative AI, we’re witnessing a remarkable revolution that’s changing the very nature of how we interact with software and digital services. This change is monumental. Leading the charge are the latest generation of AI-powered virtual assistants, aka “AI copilots”. Unlike traditional narrow AI models, these are capable of understanding user needs, intents, and questions expressed in plain, natural language.
We are talking about nothing less but the next evolution in software design and user experience that is driven by recent advances in generative AI and Large Language Models (LLMs) like OpenAI’s ChatGPT, Google Bard, or Anthrophic’s Claude.
Thanks to LLMs user interactions are no longer bound by the constraints of a traditional user interface with forms and buttons. Whether it’s creating a proposal in Word, editing an image, or opening a claim in an insurance app, users can express their needs in natural language - a profound change in our interactions with software and services.
Despite the hype about these new virtual ai assistants, our understanding of how to build an LLM-powered virtual assistant remains scant. So, if you wonder how to take advantage of LLMs and build a virtual assistant for your app, this article is for you. This post will probe into the overarching components needed to create a virtual AI assistant. We will look at the architecture and its components including LLMs, Knowledge store, Cache, Conversational Logic, and APIs.
Also:
- 9 Business Use Cases of OpenAI’s ChatGPT
- Using LLMs (OpenAI’s ChatGPT) to Streamline Digital Experiences
- ChatGPT Prompt Engineering Guide: Practical Advice for Business Use Cases

The new generation of virtual ai assistants inspires a profound change in the way we interact with software and digital services.
Virtual AI Assistants at the Example of Microsoft M365 Copilot
Advances in virtual AI assistants are closely linked to ChatGPT and other LLMs from US-based startup OpenAI. Microsoft has forged a partnership with OpenAI to bring the latest advances in AI to their products and services. Microsoft has announced these “Copilots” across major applications, including M365 and the Power Platform.
Here are some capabilities of these Copilots within M365:
- In PowerPoint, Copilot allows users to create presentations based on a given context, such as a Word document, for example by stating “Create a 10-slide product presentation based on the following product documentation.”
- In Word, Copilot can adjust the tone of writing a text or transform a few keywords into a complete paragraph. Simply type something like “Create a proposal for a 3-month contract for customer XYZ based on doc ADF.”
- In Excel, Copilot helps users with analyzing datasets, as well as with creating or modifying them. For example, it can summarize a dataset in natural langue and describe trends.
- Let’s not forget Outlook! Your new AI Copilot helps you organize your emails and calendar. It assists you in crafting email responses, scheduling meetings, and even provides summaries of key points from the ones you missed.
If you want to learn more about Copilot in M365, this youtube video provides an excellent overview. However, these are merely a handful of examples: Microsoft 365 Copilot Explained: How Microsoft Just Changed the Future of Work. The potential of AI copilots extends far beyond the scope of Office applications and can elevate any software or service to a new level. No wonder, large software companies like SAP, and Adobe, have announced plans to upgrade their products with copilot features.
Microsoft has announced a whole fleet of virtual AI assistants for its products. These range from copilots in M365 office apps to services of its Azure cloud platform.
How LLMs Enable a New Generation of Virtual AI Assistants
Virtual AI assistants are nothing but new. Indeed, their roots can be traced back to innovative ventures such as the paperclip assistant, Clippy, from Microsoft Word - a pioneering attempt at enhancing user experience. Later on, this was followed by the introduction of conventional chatbots.
Nonetheless, these early iterations had their shortcomings. Their limited capacity to comprehend and assist users with tasks outside of their defined parameters hampered their success on a larger scale. The inability to adapt to a wider range of user queries and requests kept these virtual ai assistants confined within their initial scope, restricting their growth and wider acceptance. So if we talk about this next generation of virtual ai assistants, what has truly revolutionized the scene? In essence, the true innovation lies in the emergence of LLMs such as OpenAI’s GPT4.
LLMs - A Game Changer for Conversational User Interface Design
Over time, advancements in machine learning, natural language processing, and vast data analytics transformed the capabilities of AI assistants. Modern AI models, like GPT-4, can understand context, engage in more human-like conversations, and offer solutions to a broad spectrum of queries. Furthermore, the integration of AI assistants into various devices and platforms, along with the increase in cloud computing, expanded their reach and functionality. These technological shifts have reshaped the scene, making AI assistants more adaptable, versatile, and user-friendly than ever before.
Take, for example, an AI model like GPT. A user might instruct, “Could you draft an email to John about the meeting tomorrow?” Not only would the AI grasp the essence of this instruction, but it could also produce a draft email seamlessly.
Yet, it’s not solely their adeptness at discerning user intent that sets LLMs apart. They also exhibit unparalleled proficiency in generating programmatic code to interface with various software functions. Imagine directing your software with, “Generate a pie chart that visualizes this year’s sales data by region,” and witnessing the software promptly fulfilling your command.
A Revolution in Software Design and User Experience
The advanced language understanding offered by LLMs unburdens developers from the painstaking task of constructing every possible dialog or function an assistant might perform. Rather, developers can harness the generative capabilities of LLMs and integrate them with their application’s API. This integration facilitates a myriad of user options without the necessity of explicitly designing them.
The outcome of this is far-reaching, extending beyond the immediate relief for developers. It sets the stage for a massive transformation in the software industry and the broader job market, affecting how developers are trained and what skills are prioritized. Furthermore, it alters our everyday interaction with technology, making it more intuitive and efficient.
Components of a Modern Virtual AI Assistant áka AI Copilot
By now you should have some idea of what modern virtual AI assistants are. Next, let’s look at the technical components that need to come together.
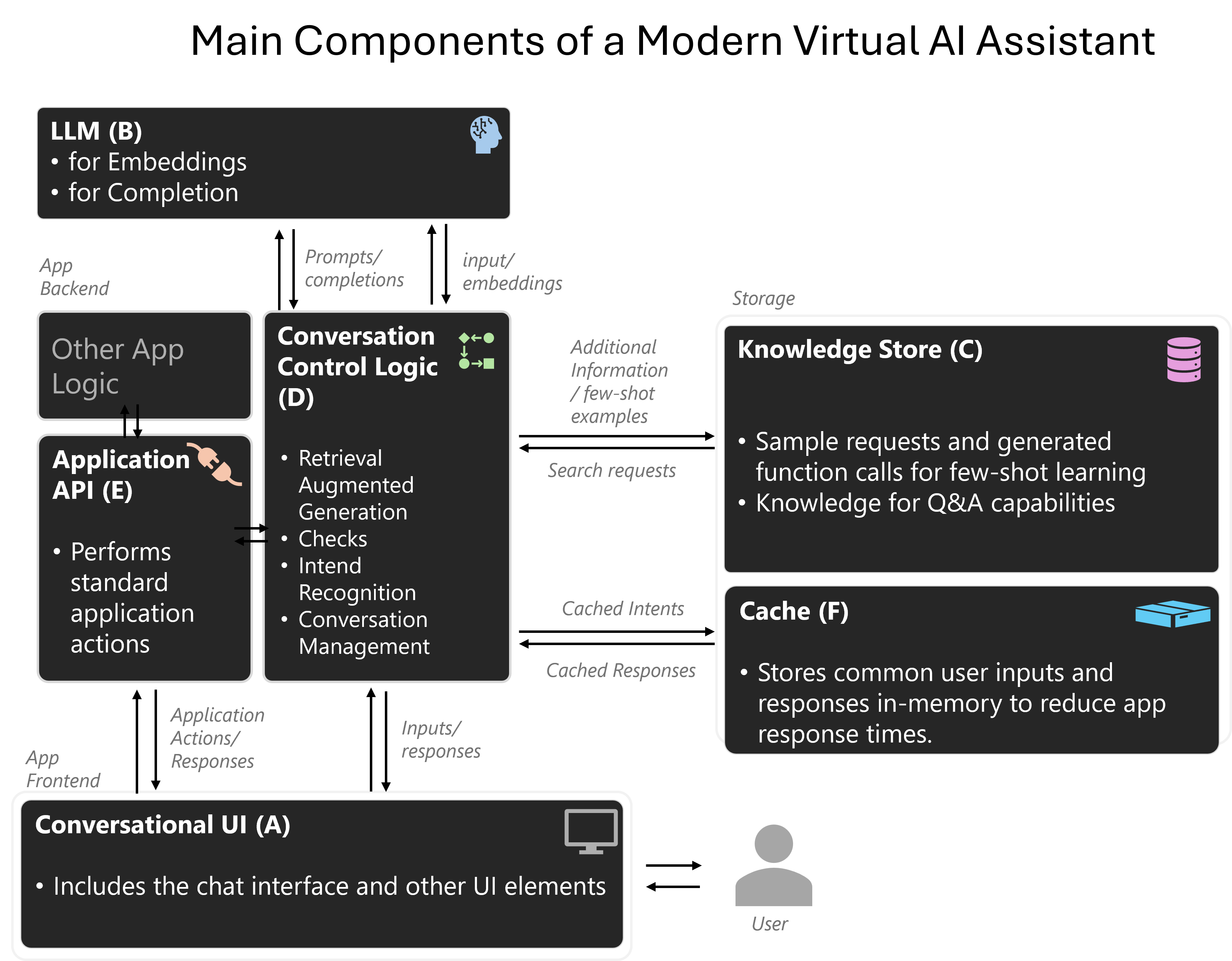
The illustration below displays the main components of an LLM-powered virtual AI assistant:
- A - Conversational UI for providing the user with a chat experience
- B - LLMs such as GPT-3.5 or GPT-4
- C - Knowledge store for grounding your bot in enterprise data and dynamically providing few-shot examples.
- D - Conversation logic for intent recognition and tracking conversations.
- E - Application API as an interface to trigger and perform application functionality.
- F - Cache for maintaining an instant mapping between often encountered user intents and structured LLM responses.
Let’s look at these components in more detail.
A) Conversational Application Frontend
Incorporating virtual AI assistants into a software application or digital service often involves the use of a conversational user interface, typically embodied in a chat window that showcases previous interactions. The seamless integration of this interface as an intrinsic part of the application is vital.
A lot of applications employ a standard chatbot methodology, where the virtual AI assistant provides feedback to users in natural language or other forms of content within the chat window. Yet, a more dynamic and efficacious approach is to merge natural language feedback with alterations in the traditional user interface (UI). This dual approach not only enhances user engagement but also improves the overall user experience.
Microsoft’s M365 Copilot is a prime example of this approach. Instead of simply feeding responses back to the user in the chat window, the virtual assistant also manipulates elements in the traditional UI based on user input. It may highlight options, auto-fill data, or direct the user’s attention to certain parts of the screen. This combination of dynamic UI manipulation and natural language processing creates a more interactive and intuitive user experience, guiding the user toward their goal in a more efficient and engaging way.
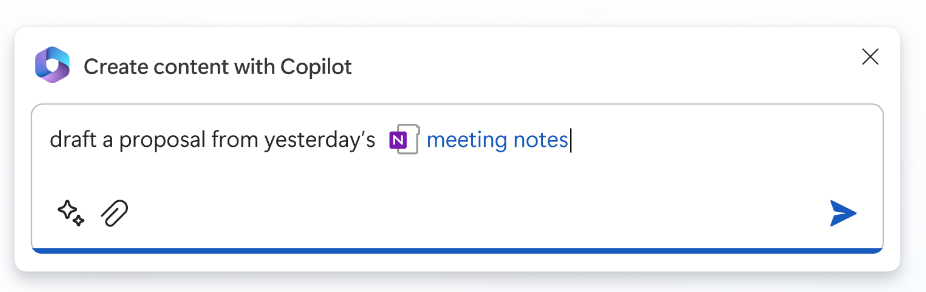
M365 Copilot chat window in M365 Office
When designing the UI for a virtual AI assistant, there are several key considerations. Firstly, the interface should be intuitive, ensuring users can easily navigate and understand how to interact with the AI. Secondly, the AI should provide feedback in a timely manner, so the user isn’t left waiting for a response. Thirdly, the system should be designed to handle errors gracefully, providing helpful error messages and suggestions when things don’t go as planned. Finally, the AI should keep the human in the loop and assist him in using AI in a safe way.
Also: Building “Chat with your Data” Apps using Embeddings, ChatGPT, and Cosmos DB for Mongo DB vCore
B) Large Language Model
At the interface between users and assistant sits the large language mode. It translates users’ requests and questions into code, actions, and responses that are shown to the user. Here, we are talking about foundational models like GPT-3.5-Turbo or GPT-4. In addition, if you are working with extensive content, you may use an embedding LLM that converts text or images into mathematical vectors as part of your knowledge store. An example, of such an embedding model, is ada-text-embeddings-002.
It’s important to understand that the user is not directly interacting with the LLM. Instead, you may want to put some control logic between the user and the LLM that steers the conversation. This logic can enrich prompts with additional data from the knowledge store or an online search API such as Google or Bing. This process of injecting data into a prompt depending on the user input is known as Retrieval Augmented Generation.
Typical tasks performed by the LLM:
- Generating natural language responses based on the user’s query and the retrieved data from the knowledge store.
- Recognizing and classifying user intent.
- Generating code snippets (or API requests) that can be executed by the application or the user to achieve a desired outcome in your application.
- Converting content into embeddings to retrieve relevant information from a vector-based knowledge store.
- Generating summaries, paraphrases, translations, or explanations of the retrieved data or the generated responses.
- Generating suggestions, recommendations, or feedback for the user to improve their experience or achieve their goals.
C) Knowledge Store
Let’s dive into the “Knowledge Store” and why it’s vital. You might think feeding a huge prompt explaining app logic to your LLM, like ChatGPT, would work, but that’s not the case. As of June 2023, LLMs have context limits. For instance, GPT-3 can handle up to 4k tokens, roughly three pages of text. This limitation isn’t just for input, but output too. Hence, cramming everything into one prompt isn’t efficient or quick.
Instead, pair your LLM with a knowledge store, like a vector database (more on this in our article on Vector Databases). Essentially, this is your system’s information storage, which efficiently retrieves data. Whichever storage you use, a search algorithm is crucial to fetch items based on user input. For vector databases, the typical way of doing this is by using similarity search.
Token Limitations
Curious about GPT models’ token limits? Here’s a quick breakdown:
- GPT-3.5-Turbo Model (4,000 tokens): About 7-8 DIN A4 pages
- GPT-4 Standard Model (8,000 tokens): Around 14-16 DIN A4 pages
- GPT-3.5-Turbo-16K Model (16,000 tokens): Approximately 28-32 DIN A4 pages
- GPT-4-32K Model (32,000 tokens): Estimated at 56-64 DIN A4 pages
D) Conversation Control Logic
Finally, the conversation needs a conductor to ensure it stays in harmony and doesn’t veer off the rails. This is the role of the conversation logic. An integral part of your app’s core software, the conversation logic bridges all the elements to deliver a seamless user experience. It includes several subcomponents. Meta prompts, for instance, help guide the conversation in the desired direction and provide some boundaries to the activities of the assistant. For example, the meta prompt may include a list of basic categories for intents that help the LLM with understanding what the user wants to do.
Another subcomponent is the connection to the knowledge store that allows the assistant to draw from a vast array of data to augment prompts handed over to the large language model. Moreover, the logic incorporates checks on the assistant’s activities and its generated content. These checks act like safety nets, mitigating risks and preventing unwanted outcomes. It’s akin to a quality control mechanism, keeping the assistant’s output in check and safeguarding against responses that might derail the user’s experience or even break the application.
E) Application API
Users expect their commands to initiate actions within your application. To fulfill these expectations, the application needs an API that can interact with various app functions. Consider the API as the nerve center of your app, facilitating access to its features and user journey. This API enables the AI assistant to guide users to specific pages, fill in forms, execute tasks, display information, and more. Tools like Microsoft Office even have their own language for this, while Python code, SQL statements, or generic REST requests usually suffice for most applications.
Applications based on a microservice architecture have an edge in this regard, as APIs are inherent to their design. If your application misses some APIs, remember, there’s no rush to provide access to all functions from the outset. You can start by supporting basic functionalities via chat and gradually expand over time. This allows you to learn from user interactions, continuously refine your offering, and ensure your AI assistant remains a useful and efficient tool for your users.
So, now that we’ve laid down the foundation, let’s buckle up and take a journey through the workflow of a modern virtual assistant. Trust me, it’s a fascinating trip ahead!
F) Cache
Implementing a cache into your virtual AI assistant can significantly boost performance and decrease response times. Particularly useful for frequently recurring user intents, caching stores the outcomes of these intents for quicker access in future instances. However, a well-designed cache shouldn’t directly store specific inputs as there is too much variety in the human language. Instead, caching could be woven into the application’s logic in the mid-layers of your OpenAI prompt flow.
This strategy ensures frequently repeated intents are handled more swiftly, enhancing user experience. It’s critical to remember that cache integration is application-specific, and thoughtful design is vital to avoid unintentionally inducing inefficiencies.
While a well-implemented cache can speed up responses, it also introduces additional complexity. Effective cache management is crucial for avoiding resource drains, requiring strategies for data storage duration, updates, and purging.
The exact impact and efficiency of this caching strategy will depend on your application specifics, including the distribution and repetition of user intents. In the upcoming articles, we’ll explore this topic further, discussing efficient cache integration in AI assistant systems.

An example of a caching technology would be Redis.
Considerations on the Architecture of Virtual AI Assistants
Designing an virtual AI assistant is an intricate process that blends cutting-edge technology with a keen understanding of user behavior. It’s about creating an efficient tool that not only simplifies tasks and optimizes workflows but also respects and preserves user autonomy. This section of our article will delve into the key considerations that guide the architecture of a virtual AI assistant. We’ll discuss the importance of user control, the strategic selection and use of GPT models, the benefits of starting simple, and the potential expansion as you gain confidence in your system’s stability and efficiency. As we journey through these considerations, remember the ultimate goal: creating a virtual AI assistant that augments user capabilities, enhances user experience, and breathes new life into software applications.
Keep the User in Control
At the heart of any virtual AI assistant should be the principle of user control. While automation can optimize tasks and streamline workflows, it is crucial to remember that your assistant is there to assist, not usurp. Balancing AI automation with user control is essential to crafting a successful user experience.
Take, for instance, the scenario of a user wanting to open a support ticket within your application. In this situation, your assistant could guide the user to the correct page, auto-fill known details like the user’s name and contact information, and even suggest possible problem categories based on the user’s descriptions. By doing so, the virtual AI assistant has significantly simplified the process for the user, making it quicker and less burdensome.
However, the user retains control throughout the process, making the final decisions. They can edit the pre-filled details, choose the problem category, and write the issue description in their own words. They’re in command, and the virtual AI assistant is there to assist, helping to avoid errors, speed up the process, and generally make the experience smoother and more efficient.
This balance between user control and AI assistance is not only about maintaining a sense of user agency; it is also about trust. Users need to trust that the AI is there to help them, not to take control away from them. If the AI seems too controlling or makes decisions that the user disagrees with, this can erode trust and hinder user acceptance.
Mix and Match Models
Another crucial consideration is the use of different GPT models. Each model comes with its own set of strengths, weaknesses, response times, costs, and token limits. It’s not just about capabilities. Sometimes, it’s unnecessary to deploy a complex GPT-4 model for simpler tasks in your workflow. Alternatives like ADA or GPT 3.5 Turbo might be more suitable and cost-effective for functions like intent recognition.
Reserve the heavy-duty models for tasks requiring an extended token limit or dealing with complex operations. One such task is the final-augmented prompt that creates the API call. If you’re working with a vector database, you’ll also need an embedding model. Be mindful that these models come with different vector sizes, and once you start building your database with a specific size, it can be challenging to switch without migrating your entire vector content.
Think Big but Start Simple
It’s always a good idea to start simple - maybe with a few intents to kick things off. As you gain experience and confidence in building virtual assistant apps, you can gradually integrate additional intents and API calls. And don’t forget to keep your users involved! Consider incorporating a feedback mechanism, allowing users to report any issues and suggest improvements. This will enable you to fine-tune your prompts and database content effectively.
As your application becomes more comprehensive, you might want to explore model fine-tuning for specific tasks. However, this step should be considered only when your virtual AI assistant functionality has achieved a certain level of stability. Fine-tuning a model can be quite costly, especially if you decide to change the intent categories after training.
Digital LLM-based Assistants - A Major Business Opportunity
From a business standpoint, upgrading software products and services with LLM-powered virtual AI assistants presents a significant opportunity to differentiate in the market and even innovate their business model. Many organizations are already contemplating the inclusion of virtual assistants as part of subscription packages or premium offerings. As the market evolves, software lacking a natural language interface may be perceived as outdated and struggle to compete.
AI-powered virtual assistants are likely to inspire a whole new generation of software applications and enable a new wave of digital innovations. By enhancing convenience and efficiency in user inputs, virtual assistants unlock untapped potential and boost productivity. Moreover, they empower users to fully leverage the diverse range of features offered by software applications, which often remain underutilized.
I strongly believe that LLM-driven virtual AI assistants are the next milestone in software design and will revolutionize software applications across industries. And remember, this is just the first generation of virtual assistants. The future possibilities are virtually endless and we can’t wait to see what’s next! Indeed, the emergence of natural language interfaces is expected to trigger a ripple effect of subsequent innovations, for example, in areas such as standardization, workflow automation, and user experience design.
Summary
In this article, we delved into the fascinating world of virtual AI assistants, powered by LLMs. We started by exploring how the advanced language understanding of LLMs is revolutionizing software design, easing the workload of developers, and reshaping user experiences with technology.
Next, we provided an overview of the key architectural components of a modern virtual AI assistant: the Conversational Application Frontend, Large Language Model, Knowledge Store, and Conversation Control Logic. We also introduced the concept of an Application API and the novel idea of a Cache for storing and quickly retrieving common user intents. Each component was discussed in the context of their roles and how they work together to create a seamless, interactive, and efficient user experience.
We then discussed architecture considerations, emphasizing the necessity of maintaining user control while leveraging the power of AI automation. We talked about the judicious use of different GPT models based on task requirements, the advantages of starting with simple implementations and progressively scaling up, and the benefits of user feedback in continuously refining the system.
This journey of ‘AI in Software Applications’, from concept to reality, isn’t just about innovation. It’s about unlocking ‘Innovative Business Models with AI’ and boosting user engagement and productivity. As we continue to ride the wave of ‘Natural Language Processing for Software Automation’, the opportunities for harnessing the power of virtual AI assistants are endless. Stay tuned as we explore the workflows further in the next article.

In this article, we have gone through the components of an LLM-powered virtual assistant aka “AI copilot”. In the next article, we will dive deeper into the processing logic and follow a prompt into the engine of an intelligent assistant.
Sources and Further Reading
- Natural Language Commanding via Program Synthesis
- Wikipedia.org/Office Assistant
- Microsoft Blogs - Introducing Microsoft 365 Copilot
- Reuters - Sap CEO Huge Growth Potential in Generative AI
- Microsoft Outlines Framework for Building AI Apps and Copilots, Expands AI Plugin Ecosystem
- Google Announces Digital Assistants in their Worksuite
- Youtube, Microsoft Mechanics - How Microsoft 365 Copilot works
- Youtube, Lisa Crosby - Microsoft 365 Copilot Explained: How Microsoft Just Changed the Future of Work
Frequently asked questions
- What are the main components of an LLM-powered AI assistant?
- Six: a conversational frontend (chat UI), the language model, a knowledge store to ground the assistant in your data, conversation control logic for intent recognition and guardrails, an application API to trigger app functionality, and a cache for frequently recurring intents.
- Why use a knowledge store instead of putting everything in the prompt?
- Because LLMs have token limits, you cannot fit all of an application’s data and logic into a single prompt. A knowledge store such as a vector database holds your information and retrieves the relevant items — usually via similarity search — to inject into the prompt based on the user’s input.
- Should you use one model or several?
- Several. Simpler tasks like intent recognition can use cheaper, faster models, while a stronger model is reserved for complex operations such as the final augmented prompt that constructs the API call.




1 Commentarchived from the original site