

Just a year ago, ChatGPT was launched, and it has since catalyzed a seismic shift in the AI landscape. Given the astonishing capabilities of generative AI and the rapid evolution of foundation models, one question has risen to the forefront of discussions: What will be the impact of foundation models on classic machine learning and so-called “narrow AI”?
The opinions on this topic are sharply divided. Some are convinced that foundation models are poised to completely overshadow traditional machine learning methods. Others remain steadfast in their belief that classic ML techniques have enduring value. As we’ll explore in this article, the reality is far more nuanced than a straightforward “yes” or “no.”
To dissect this complex issue, we’ll delve into a range of application domains, from classification and regression to natural language processing (NLP), clustering, and computer vision, among others. We’ll also discuss a few concepts and terms along the way. On top of that, we will examine additional considerations such as interpretability, computational demands, and reliability.
Having worked a few years classic ml and since the end of 2022 mostly on Generative AI, I would like to share a few thoughts. Please take them with some caution, as they are mostly based on personal experience in the field and my conversations with organizations on how they can benefit from generative AI.
The Beginnings Classic Machine Learning
When I started my career a few years ago in 2017 the world was an entirely different one. There were already some tools that would help with that but instead of Python, but most data scientists were still using R (yes, yes, its still being used). There was also no ChatGPT, and the closest thing available was BERT; which was introduced by Google in 2017 and technologially marked an important step towards todays foundation models.
If you you wanted to use AI in 2017, you would typically need to build your own model for your specific use case. You had to collect the data, prepare it (still today takes most of the time), and then train a model, test it and deploy it into production. Oh and then monitor it.
This is the classic data sciense process and it is complex, with a lot of steps that in many companies took several month. And there is a catch to it. At the end of the process, when you have built your model, it is what we call today narrow AI.
Why Narrow? Because the model is only there for a specific use case. If you have a slightly different use case, you would typically need to train a new model. As a result, companies that were successful in building ML models, quickly end up with a large number of models they need to run and monitor, which adds additional complexity.
Pretrained Models – Comodity AI
There are certain AI applications that we just see again and again and that stay mostly the same. Many of these applications are in the area of computer vision and audio recognition.
An example, is face recognition. Cloud providers soon recognized that the models they often had built for their own purpose, could also be useful to their customers. Face recognition, voice recognition, or information extraction from invoices have become commidities. These models are relatively complex to built from scratch but have a high degree of standardization. So customers who want to use these models often decide to not build them themselves but buy them as a service from an external provider.
Yet, these models are still narrow AI because they can only do one thing.
Foundation Models
With ChatGPT, LLMA2, Bard, etc. we are embarking from the world of narrow AI and enter the realm of foundation models. Its a paradigm shift not only in the way we create AI models but also in the way we interact with them.
Foundation models are fundamentally different from classic ML in the way they are trained. Instead of using the data from a specific problem, and training a model, foundation models are trained on large amounts of natural language – a major part of what is available today in the public internet in different languages, incl. wikipedia, computer code, etc. The training process takes up to several month, costs millions of dollar and results in extremely capable models.
Foundation models built on several technologies that were developed throughout the years. A few examples:
- Machine learning: Instead of explicitly programming foundation models, they learn from the provided data and identify patterns.
- Transformers: Were a milestone and part of the BERT model. It introduces an effective way of training word prediction models with a high degree of parallelization.
- Supervised learning: foundation models are trained on labeled datasets.
- To further improve the models, foundation models are trained using reinformcenent learning with human feedback.
- Deep learning: Foundation models use large neural networks with a large number of layers and neurons.
The sheer size of these models make them possible to solve a whole lot of tasks. However, there are things that these models were so far struggling with, for example, solving math problems, halluzinations, etc.And regardless of the task you communicate and instruct foundation models via a prompt.
What can Foundation Models Do Compared to Classic ML?
Foundation models and classic machine learning (ML) techniques embody different approaches to problem-solving in the realm of artificial intelligence, each with its distinct advantages, disadvantages, and ideal use-cases. Here’s a nuanced comparison across various application domains and aspects.
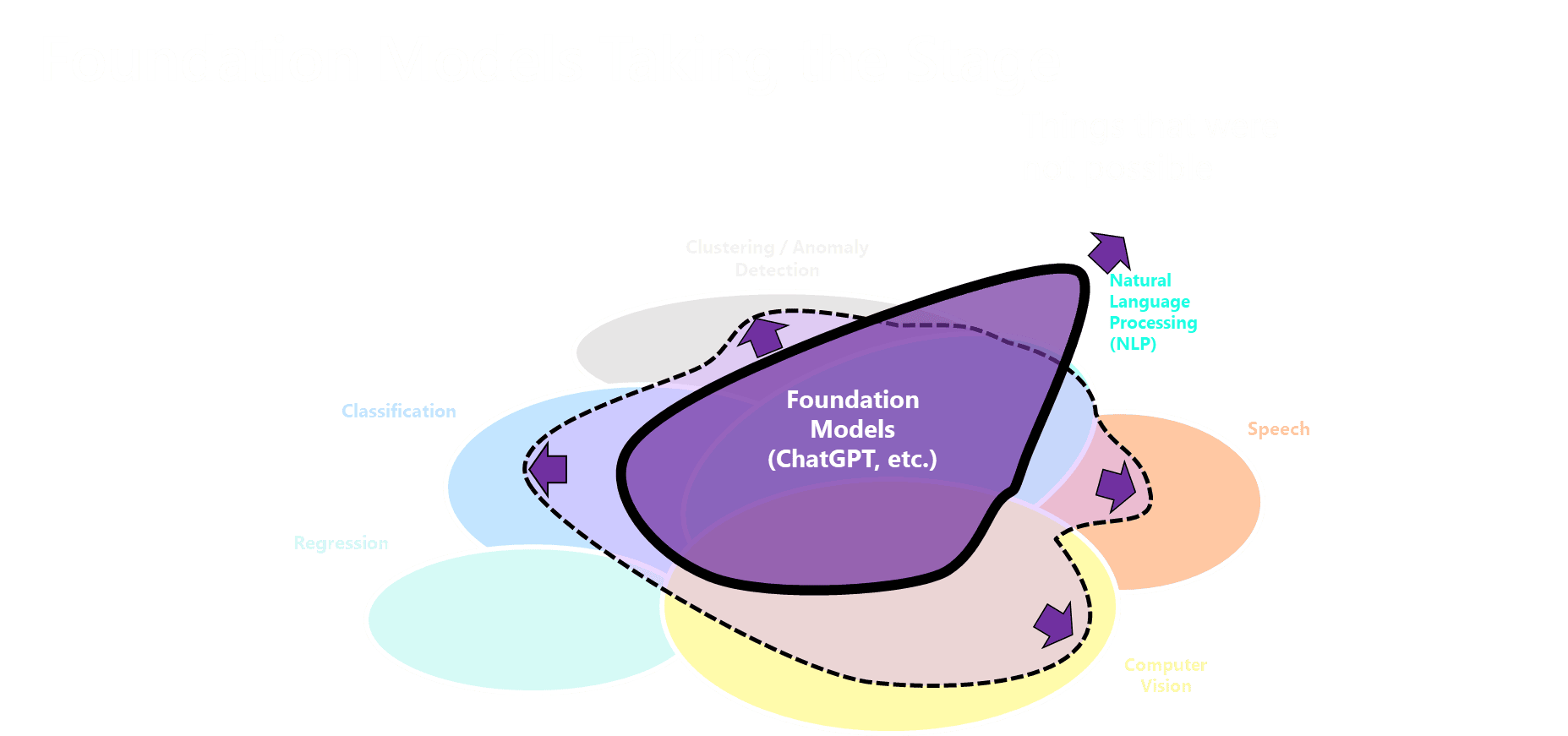
The classic ML field is still in several application domains that have emerged over time. These areas can be roughly differentiated into:
- classification (of structured inputs; two and multiclass)
- regression & time series forecasting
- clustering
- outlier detection
- recommender systems
- natural language processing (NLP)
- computer vision
- audio processing
I belive these categories cover at least 90% of the use cases in the area of machine learning. Next let’s take a closer look at these categories. I will be mostly focusing on performance and discuss other aspects at the end of this article.
#1 Classification (on Tabular Datasets)
In the domain of classification, classic ML approaches like logistic regression, decision trees, and SVMs have been historically employed. If you have been following my blog then you know i have also explained a few of their applications (Classifying Purchase Intention of Online Shoppers with Python etc.).
Performance
These classic algorithms work well when the data is structured and the relationship between the input and the output is relatively straightforward. A classic example is the titantic dataset where the goal is to predict surval of passengers based on age, gender, cabin, etc. Foundation models, due to their ability to learn from vast amounts of data, not only take into account the structured variablesbut potetially also make sense of additional information such as names etc., that would otherwise be more difficult to use. In other cases, LLMs could also make sense of text snippets and extract additional information.
LLMs perform quite well on simpler classification tasks, but for more complex ones with many categories or high-dimensional data, custom trained and hyperparameter-tuned models outperform them. However, the potential in traditional algorithm for further improvements is rather low. On the other hand, foundation models are likely to improve further in the coming year and will thus likely see increasing adoption for more complex classification tasks.
Limitations
Indeed, LLMs offer unparalleled flexibility in this domain, especially with text-based tasks. Their ability to generalize over different types of data makes them highly versatile. Their auto-adjustment to data drift can save costs on retraining, a significant benefit.
For complex cases, the bgiggest limitation is the token limit. Even for LLM finetuning, you will have a hard time training the model with a large number (several hundrets) of input variables. As long as the token limit does not grow considerably, classification tasks are limited to cases with medium complexity. With better fine-tuning options and longer token limits, the use of foundation models will likely grow.
Outlook
Classic ML and foundation models will coexist, with foundation models gaining more traction as they overcome current limitations like token limits.
#2 Regression and Time Series Forecasting
Methods like Linear Regression, ARIMA (AutoRegressive Integrated Moving Average), and Prophet have long been the go-to choices for both regression and time series analysis. Their popularity stems from there interpretability and easy of implementation. Foundation models are not great with mathematics but can create solid forecasts. However, they lack the interpretability and reliability that is often key for forecasting use cases. In addition, for longer time series, the limited context window becomes a problem again, especially as floadting numbers take a lot of tokens. On the other hand, foundation models may be able to identify more complex patterns that traditional techniques would likely oversee.
Also: Stock Market Prediction using Multivariate Time Series and Recurrent Neural Networks in Python
Outlook: At the moment, regression tasks are a domain where classic machine learning has an edge over foundation models. It remainst o be seen how long this will last.
NLP
NLP comprises a variety of disciplines from recognition, text completion, text classification and information extraction, reasoning over text. But with the rise of BERT and ROBERTA this bastion of data science begun to crumble. Now with modern LLMs, it seems entirely lost to foundation models.
In all of these fields, LLMs like GPT-4 show superior performance. The large-scale training and vast data encompassed by foundation models make them highly efficient at generation tasks, often surpassing custom models. GPT-4 and ChatGPT were both able to pass numerous exams inlcuding the Bar exam.
Outlook: Foundation models are already ahead and likely to take the rest of the entire share.
Clustering
As LLMs generate meaningful embeddings, they indeed offer exciting prospects for clustering tasks. Traditional clustering algorithms might still be useful for specific use cases or where interpretability is crucial.
Embeddings work well for clustering techniques. Its the same technique that is based on the distance between objects and works both with numeric inputs as well as with text in different languages.
However, classic ml algorithms were always struggling with more complex patterns in data and as of now I have reason to believe that the situation is similar with LLMs. However, this assessment is only for the traditional LLMs but not for vision models. GPT-4 V was just released a few weeks and its image interpretation capabilities are crazy good. This model will also be able to interpret outliers and identify unusual geometric shapes in cluster diagrams that would be hard to detect with traditional models. Its a game changer for outlier detection and clastering alike.
Outlook: Foundation models taking an increasing spot
Outlier Detection
While outlier detection is performed differently from clustering in classic ml, foundation models perform a similar technique both for clustering and outlier detection.
While LLMs are good at detecting patterns, traditional ML has established algorithms for outlier detection that work exceptionally well in controlled settings, especially when we have a clear understanding of the data’s distribution.
When we are talking about outlier detection, classic ML models will give you a more fine-grained control over what is considered an outlier and here classic ml I believe will stay relevant for
Outlook: Classic ML models remain relevant, although foundation models will be used for certain tasks
Computer Vision
Your differentiation is spot on. While foundation models have made strides in general computer vision tasks, specialized tasks like medical imaging or self-driving cars require models built and trained for that specific purpose.
Outlook: The future will likely have a coexistence between custom trained special models for specific tasks like autononoums systems, and simpler more generic tasks like face detection, object detection and tagging. At the same time, foundation models have added a few new disciplines like image interpreation and image generation, where custom models have never been able to produce good results.
For specific task like getting exact coordinates, computer vision models will have certain limitations. Here traditional models and pretrained models will have an edge.
Outlook: Foundation models taking a large share of computer vision tasks.
Audio Processing
As foundation models expand their capabilities, they’re likely to dominate tasks like transcription or synthesis. However, specialized tasks such as voice biometrics or unique sound classifications might still rely on custom models.
Outlook: Foundation models taking the share entirely
Recommender Systems
Traditional recommendation systems, especially those utilizing collaborative filtering or matrix factorization, have been honed over years and work remarkably well. LLMs can augment these systems by providing context-rich content recommendations or by understanding nuanced user preferences.
In summary, while LLMs have certainly expanded the frontiers of what’s possible, especially in the realm of NLP, they won’t replace traditional ML/DL across the board. Instead, they complement existing systems, offering new capabilities and efficiencies. The choice between the two often boils down to the specifics of the task, the available data, and the desired outcomes. The future likely holds a symbiotic relationship where both coexist, each playing to its strengths.
Outlook: I am unsure. I could imagine that foundation are increasingly be used in combination with classic models.
Additional Aspects:
- Interpretability:
- Classic ML: Often more interpretable, which is crucial for understanding model decisions in sensitive domains.
- Foundation Models: The “black box” nature makes them less interpretable, although efforts like LIME or SHAP are attempting to mitigate this issue.
- Consistency and reliability:
- Classic ML results are still more predictable. In cases of high stakes, classic ML will be used more than generative AI.
- Deployment and Maintenance:
- Classic ML: Easier to deploy and maintain due to their simplicity and lower resource requirements.
- Foundation Models: Can be resource-intensive to deploy and maintain, especially at the scale necessary for real-world applications.
- Customization:
- Classic ML: Certain well-understood problems have commoditized solutions available.
- Foundation Models: Pushing the boundary of commoditization further by providing powerful, generalized solutions that can be fine-tuned for specific tasks.
Summary
Not long ago, if somebody would have asked me, if these models could entirely replace classic machine learning, i would have said, of course not, they will still have a place. There were just too many fields, where training a custom machine learning model makes just more sense. Computer vision is a great example, as soon as you want to count specific objects, you would typeically not come around training a custom model for that. Of course you would use existing libraries and maybe pretrained models, but still you would have to do a main part of the job.
Foundation models are undeniably transformative, especially in domains like NLP and Computer Vision, where they often outperform classical ML techniques. However, the necessity for interpretability, lower resource requirements, and specific problem-tailored solutions in certain scenarios ensures that classical ML will continue to hold its relevance. The evolution towards more capable foundation models doesn’t signify the end of classical ML, but rather presents an enriched tapestry of tools and methodologies that practitioners can draw upon to tackle complex problems in the AI landscape.
How does it look today? A few month later GPT-4 has been released, which is already much better at solcingf math problems than GPT3.5. Only a few weeks before, GPT-4 V has been released, which is extremely good at interperting images.
Sources and Further Reading
List: Here Are the Exams ChatGPT and GPT-4 Have Passed so Far (businessinsider.com)
