Stock Market Prediction using Multivariate Time Series and Recurrent Neural Networks in Python

Regression models based on recurrent neural networks (RNN) can recognize patterns in time series data, making them an exciting technology for stock market forecasting. What distinguishes these RNNs from traditional neural networks is their architecture. It consists of multiple layers of long-term, short-term memory (LSTM). These LSTM layers allow the model to learn patterns in a time series that occur over different periods and are often difficult for human analysts to detect. We can train such models with one feature (univariate forecasting models) or multiple features (multivariate models). Multivariate Models can take more data into account, and if we provide them with relevant features, they can make better predictions. This tutorial uses Python and Keras to implement a multivariate RNN for stock price prediction. We define the architecture of our regression model and then train this model to predict the NASDAQ index.
The remainder of this tutorial proceeds in two parts: We start with a brief intro in which we compare modeling univariate and multivariate time series data. Then we turn to the hands-on part, in which we prepare the multivariate time series data and use it to train a neural network in Python. The model is a recurrent neural network with LSTM layers that forecasts the NASDAQ stock market index. Finally, we evaluate the performance of our model and make a forecast for the next day.
Disclaimer
This article does not constitute financial advice. Stock markets can be very volatile and are generally difficult to predict. Predictive models and other forms of analytics applied in this article only serve the purpose of illustrating machine learning use cases.

Stock market forecasting has become an exciting application for recurrent neural networks.
Univariate vs. Multivariate Time Series Models
Multivariate models and univariate models differ in the number of their input features. While univariate models consider only a single feature, multivariate models use several input variables (features). In stock market forecasting, we can create additional features from price history. Examples are performance indicators such as moving averages, the RSI, or the Sales Volume. We can also include features from other sources, for example, social media sentiment, weather forecasts, etc. Multivariate models that have additional relevant information available have a chance to outperform univariate models. However, this is only true if the features are relevant and are indicative of future price movements.
Preparing data for training univariate models is more straightforward than for multivariate models. If you are new to time series prediction, you might want to look at my earlier articles. These explain how to develop and evaluate univariate time series models:
- Stock Market Forecasting using Univariate Models and Python
- Multi-step Time Series Forecasting with Python: Step-by-Step Guide
- Stock Market Prediction – Adjusting Time Series Prediction Intervals
- Evaluating Time Series Forecasting Models with Python
Univariate Prediction Models
In time series regression, the standard approach is to train a model using past values from the time series that need to be predicted. The assumption is that the value of a time series at time t is closely related to the previous time steps t-1, t-2, t-3, and so on. This approach is similar to chart analysis, which involves identifying patterns in a price chart that can indicate future movements. Both approaches rely on the ability to identify recurring patterns in the data and make accurate predictions based on them. The performance of the model or analysis depends on the ability to identify these patterns and draw the right conclusions from them.
Several techniques can be used to improve the performance of time series regression models, including feature engineering, hyperparameter optimization, and ensemble methods. In addition to these techniques, it is also important to carefully evaluate the performance of the model using appropriate metrics, such as mean squared error or mean absolute error, and to continuously monitor the model’s performance to ensure it remains accurate over time.
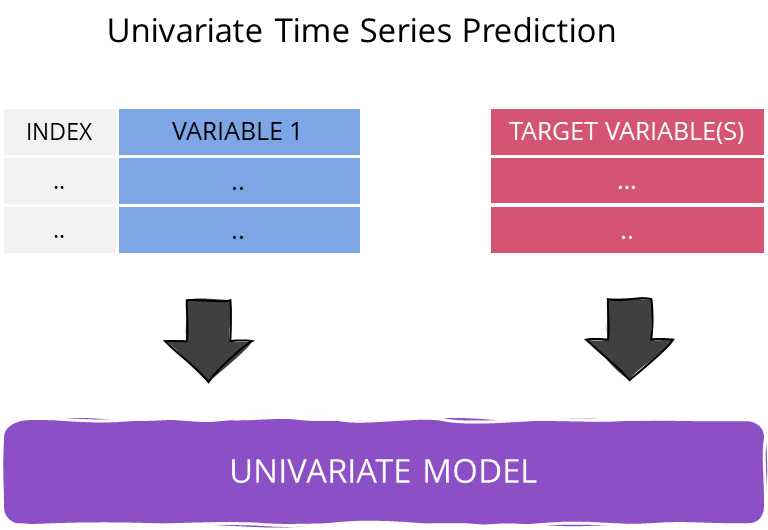
Univariate Time Series Prediction
Multivariate Prediction Models
Predicting the price of a financial asset is a challenging task due to the numerous variables that can influence it, including economic cycles, political events, unforeseen occurrences, psychological factors, market sentiment, and even the weather. These variables are often interdependent, which makes statistical modeling even more complex. While multivariate models can take into account several factors, they are still a simplification of reality and may not fully capture the complexity of the market. On the other hand, univariate models only consider a single dependent variable, ignoring the other dimensions.
Even with good features, predicting financial prices can be difficult because patterns and market rules may change frequently. As a result, models may make mistakes. However, as Georg Box famously said, “All models are wrong, but some are useful.” Despite their limitations, multivariate models can provide a more detailed representation of reality compared to univariate models, and can still be useful in forecasting financial prices.
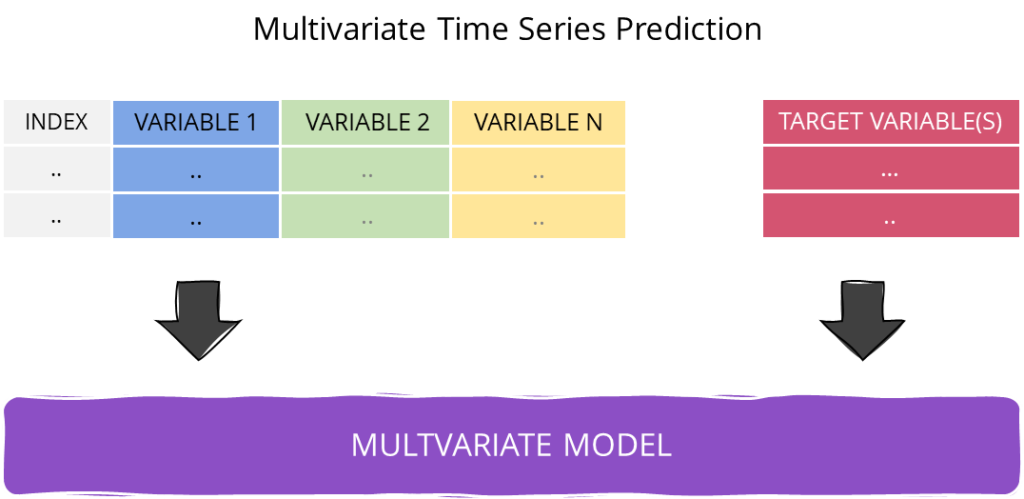
Multivariate Time Series Prediction
Implementing a Multivariate Time Series Prediction Model in Python
Now that we have a solid understanding of multivariate time series forecasting, it’s time to put our knowledge into practice by building a model using Python and TensorFlow. Specifically, we will create a multivariate recurrent neural network (RNN) to predict the NASDAQ stock market index. RNNs are well-suited for time series forecasting because they can process sequential data, considering the dependencies between past and future events.
To build our RNN model, we will need to go through several essential steps.
- Creating features and scaling: This involves loading and preparing the time series data for modeling, including selecting the time period and relevant features and scaling the data.
- Splitting the data: We split the data into train and test sets.
- Sliding window approach: The time series data is sliced into mini-batches using the sliding window approach.
- Model design and training: The appropriate architecture for the RNN model is chosen, and an optimization algorithm is used to adjust the model’s weights and biases to minimize prediction error.
- Model validation and predictions: We evaluate the model’s performance by comparing the predicted values to the actual values of the NASDAQ index. In addition, we will use the model to make predictions about future events.
- Unscaling the predictions: The predictions are unscaled to bring them back to their original scale.
The code is available on the GitHub repository.
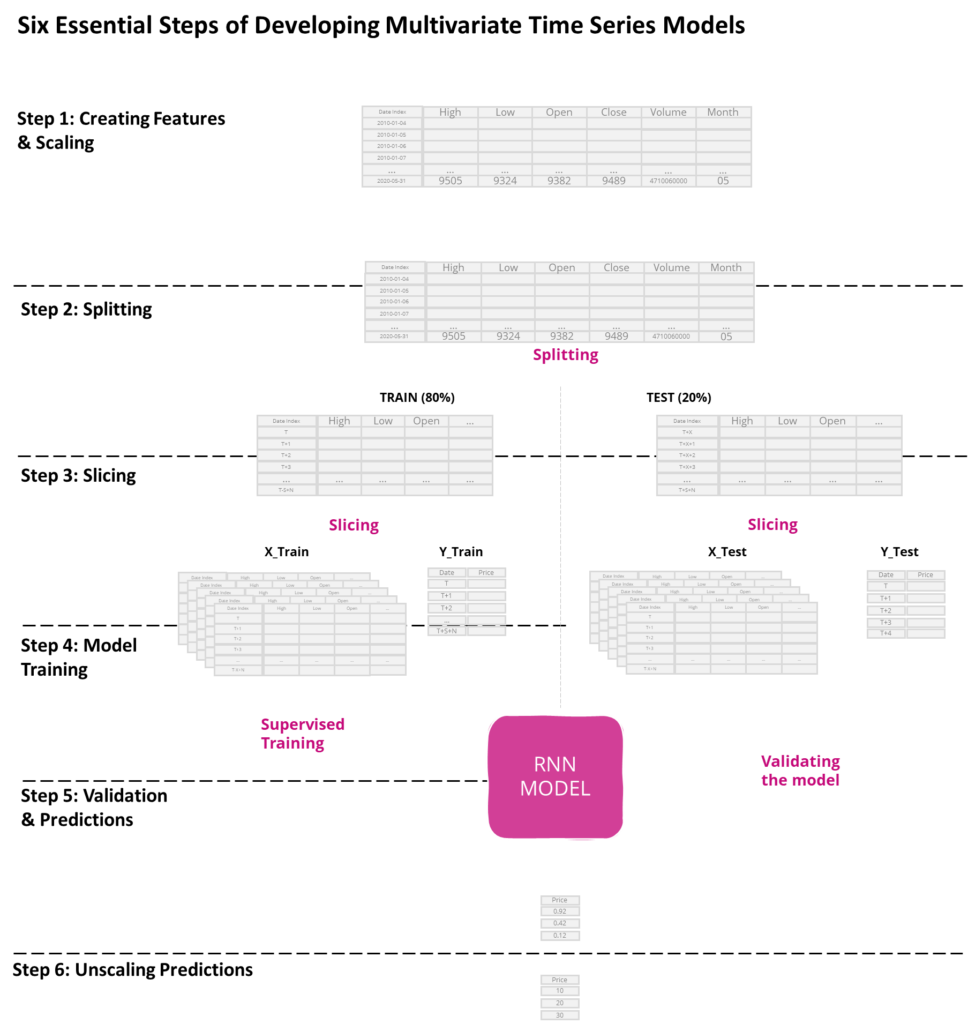
Six Essential Steps for Developing a Multivariate Time Series Model
Prerequisites
Before starting the coding part, make sure that you have set up your Python 3 environment and required packages. If you don’t have a Python environment, follow the steps in this tutorial to set up the Anaconda environment.
Also, make sure you install all required packages. In this tutorial, we will be working with the following standard packages:
In addition, we will be using Keras(2.0 or higher) with Tensorflow backend, the machine learning library sci-kit-learn, and the pandas-DataReader.
You can install packages using console commands:
- pip install
- conda install
(if you are using the anaconda packet manager)
Step #1 Load the Time Series Data
Let’s start by loading price data on the NASDAQ composite index (symbol: ^IXIC) from yahoo.finance.com into our Python project. To download the data, we use Pandas DataReader - a popular Python library that provides functions to extract data from various sources on the web. Alternatively, you can also use the “yfinance” library.
We provide the technical symbol for the NASDAQ index, “^IXIC.” Alternatively, you could use other asset symbols, for example, BTC-USD, to get price quotes for Bitcoin. In addition, we limit the data in the API request to the timeframe between 2010-01-01 and the current date.
Running the code below will load the data into a new DataFrame object. Be aware that input data and predictions will vary depending on when you execute the code.
# Time Series Forecasting - Multivariate Time Series Models for Stock Market Prediction
import math # Mathematical functions
import numpy as np # Fundamental package for scientific computing with Python
import pandas as pd # Additional functions for analysing and manipulating data
from datetime import date, timedelta, datetime # Date Functions
from pandas.plotting import register_matplotlib_converters # This function adds plotting functions for calender dates
import matplotlib.pyplot as plt # Important package for visualization - we use this to plot the market data
import matplotlib.dates as mdates # Formatting dates
import tensorflow as tf
from sklearn.metrics import mean_absolute_error, mean_squared_error # Packages for measuring model performance / errors
from tensorflow.keras import Sequential # Deep learning library, used for neural networks
from tensorflow.keras.layers import LSTM, Dense, Dropout # Deep learning classes for recurrent and regular densely-connected layers
from tensorflow.keras.callbacks import EarlyStopping # EarlyStopping during model training
from sklearn.preprocessing import RobustScaler, MinMaxScaler # This Scaler removes the median and scales the data according to the quantile range to normalize the price data
import seaborn as sns # Visualization
sns.set_style('white', { 'axes.spines.right': False, 'axes.spines.top': False})
# check the tensorflow version and the number of available GPUs
print('Tensorflow Version: ' + tf.__version__)
physical_devices = tf.config.list_physical_devices('GPU')
print("Num GPUs:", len(physical_devices))
# Setting the timeframe for the data extraction
end_date = date.today().strftime("%Y-%m-%d")
start_date = '2010-01-01'
# Getting NASDAQ quotes
stockname = 'NASDAQ'
symbol = '^IXIC'
# You can either use webreader or yfinance to load the data from yahoo finance
# import pandas_datareader as webreader
# df = webreader.DataReader(symbol, start=start_date, end=end_date, data_source="yahoo")
import yfinance as yf #Alternative package if webreader does not work: pip install yfinance
df = yf.download(symbol, start=start_date, end=end_date)
# Create a quick overview of the dataset
df.head()Tensorflow Version: 2.5.0
Num GPUs: 1
[*********************100%***********************] 1 of 1 completed
Open High Low Close Adj Close Volume
Date
2009-12-31 2292.919922 2293.590088 2269.110107 2269.149902 2269.149902 1237820000
2010-01-04 2294.409912 2311.149902 2294.409912 2308.419922 2308.419922 1931380000
2010-01-05 2307.270020 2313.729980 2295.620117 2308.709961 2308.709961 2367860000
2010-01-06 2307.709961 2314.070068 2295.679932 2301.090088 2301.090088 2253340000
2010-01-07 2298.090088 2301.300049 2285.219971 2300.050049 2300.050049 2270050000The data looks as expected and has the following columns:
- High - the daily high
- Low - the daily low
- Open - the opening price
- Close - the closing price
- Volume - the daily trading volume
- Adj Close - the adjacent closing price
Step #2 Explore the Data
Let’s first familiarize ourselves with the data before processing them further. Line plots are an excellent choice to gain a quick overview of time series data. By running the code below, we loop over the columns to plot a line chart for each column of the dataframe.
# Plot line charts
df_plot = df.copy()
ncols = 2
nrows = int(round(df_plot.shape[1] / ncols, 0))
fig, ax = plt.subplots(nrows=nrows, ncols=ncols, sharex=True, figsize=(14, 7))
for i, ax in enumerate(fig.axes):
sns.lineplot(data = df_plot.iloc[:, i], ax=ax)
ax.tick_params(axis="x", rotation=30, labelsize=10, length=0)
ax.xaxis.set_major_locator(mdates.AutoDateLocator())
fig.tight_layout()
plt.show()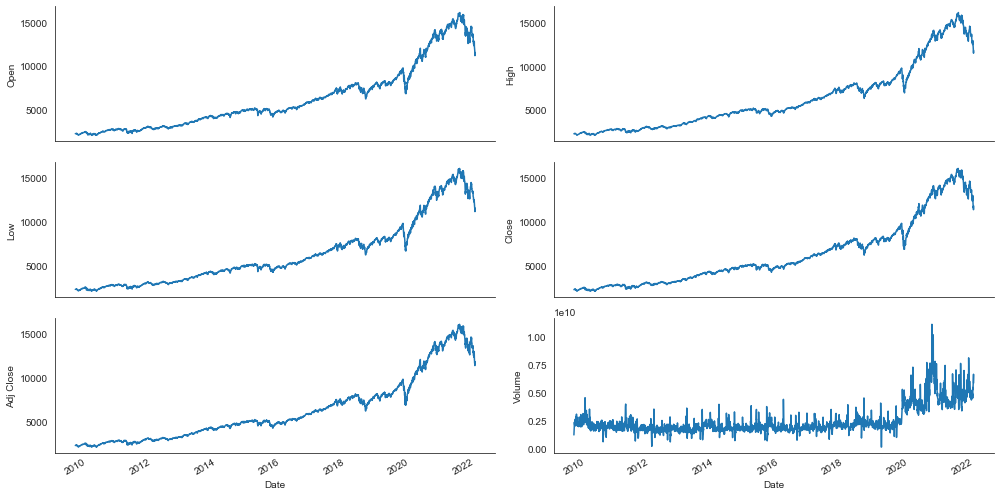
The line plots look as expected. We continue with preprocessing and feature engineering.
Step #3 Feature Selection and Scaling
Before we can train the neural network, we need to transform the data into a processable shape. In this section, we perform the following tasks:
- Selecting features
- Scaling the data to a standard value range
3.1 Selecting Features
First, we will select the features upon which we want to train our neural network. The selection and engineering of relevant feature variables is a complex topic. We could also create additional features such as moving averages, but I want to keep things simple. Therefore, we select features that are already present in our data. To learn more about feature engineering for stock market prediction, check out the relataly feature engineering tutorial.
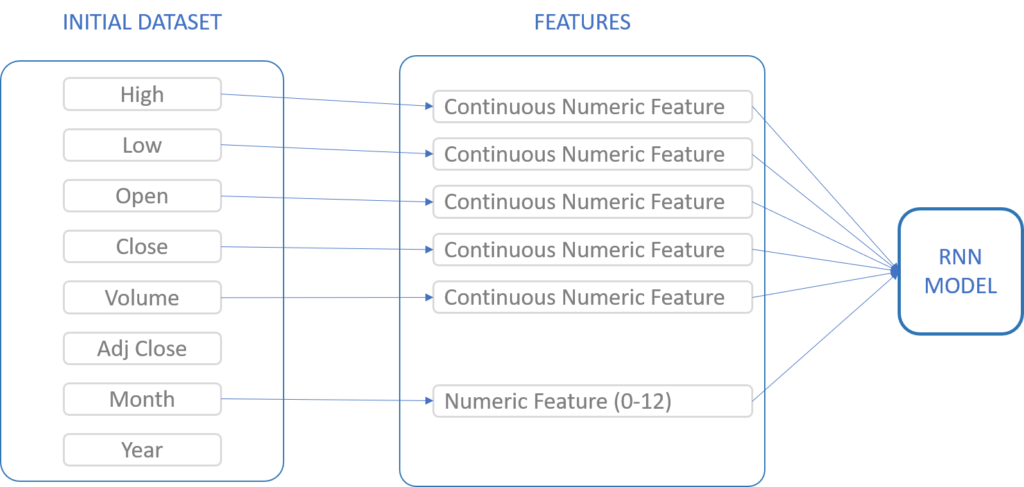
Feature Selection of Multivariate Time Series Models
Running the code below selects the features. We add a dummy column to our record called “Predictions,” which will help us later when we need to reverse the scaling of our data.
# Indexing Batches
train_df = df.sort_values(by=['Date']).copy()
# List of considered Features
FEATURES = ['High', 'Low', 'Open', 'Close', 'Volume'
#, 'Month', 'Year', 'Adj Close'
]
print('FEATURE LIST')
print([f for f in FEATURES])
# Create the dataset with features and filter the data to the list of FEATURES
data = pd.DataFrame(train_df)
data_filtered = data[FEATURES]
# We add a prediction column and set dummy values to prepare the data for scaling
data_filtered_ext = data_filtered.copy()
data_filtered_ext['Prediction'] = data_filtered_ext['Close']
# Print the tail of the dataframe
data_filtered_ext.tail()FEATURE LIST
['High', 'Low', 'Open', 'Close', 'Volume']
High Low Open Close Volume Prediction
Date
2022-05-09 11990.610352 11574.940430 11923.030273 11623.250000 5911380000 11623.250000
2022-05-10 11944.940430 11566.280273 11900.339844 11737.669922 6199090000 11737.669922
2022-05-11 11844.509766 11339.179688 11645.570312 11364.240234 6120860000 11364.240234
2022-05-12 11547.330078 11108.759766 11199.250000 11370.959961 6647400000 11370.959961
2022-05-13 11856.709961 11510.259766 11555.969727 11805.000000 5868610000 11805.0000003.2 Scaling the Multivariate Input Data
Another necessary step in data preparation for neural networks is scaling the input data. Scaling will increase training times and improve model accuracy. The scikit-learn package offers different scaling approaches. We use the MinMaxScaler to scale the input data to a range between 0 and 1.
A model that is trained on scaled data will also produce scaled predictions. Therefore, when we make predictions later with our model, we must not forget to scale the predictions back. The scaler_model will adapt to the shape of the data (6-dimensional). However, our predictions will be one-dimensional. Because the scaler has a fixed input shape, we cannot simply reuse it for unscaling our model predictions. To unscale the predictions later, we create an additional scaler that works on a single feature column (scaler_pred).
# Get the number of rows in the data
nrows = data_filtered.shape[0]
# Convert the data to numpy values
np_data_unscaled = np.array(data_filtered)
np_data = np.reshape(np_data_unscaled, (nrows, -1))
print(np_data.shape)
# Transform the data by scaling each feature to a range between 0 and 1
scaler = MinMaxScaler()
np_data_scaled = scaler.fit_transform(np_data_unscaled)
# Creating a separate scaler that works on a single column for scaling predictions
scaler_pred = MinMaxScaler()
df_Close = pd.DataFrame(data_filtered_ext['Close'])
np_Close_scaled = scaler_pred.fit_transform(df_Close)Out: (2619, 6)Step #4 Transforming the Multivariate Data
Next, we train our multivariate regression model based on a three-dimensional data structure. The first dimension is the sequences, the second dimension is the time steps (mini-batches), and the third dimension is the features. The illustration below shows the steps to bring the multivariate data into a shape our neural model can process during training. We must keep this form and perform the same steps when using the model to create a forecast.
An essential step in the preparation process is slicing the data into multiple input data sequences with associated target values. We write a simple Python script that uses a “sliding window.” This approach moves a window through the time series data, adding a sequence of multiple data points to the input data with each step. The target value (e.g., Closing Price) follows this sequence, and we store it in a separate target dataset. Then we push the window one step further and repeat these activities. This process results in a data set with many input sequences (mini-batches), each with a corresponding target value in the target record. This process applies both to the training and the test data.

Sliding Window
We will apply the sliding window approach to our data. The result is a training set (x_train) containing 2258 input sequences, each with 50 steps and six features. The related target dataset (y_train) has 2258 target values.
# Set the sequence length - this is the timeframe used to make a single prediction
sequence_length = 50
# Prediction Index
index_Close = data.columns.get_loc("Close")
# Split the training data into train and train data sets
# As a first step, we get the number of rows to train the model on 80% of the data
train_data_len = math.ceil(np_data_scaled.shape[0] * 0.8)
# Create the training and test data
train_data = np_data_scaled[0:train_data_len, :]
test_data = np_data_scaled[train_data_len - sequence_length:, :]
# The RNN needs data with the format of [samples, time steps, features]
# Here, we create N samples, sequence_length time steps per sample, and 6 features
def partition_dataset(sequence_length, data):
x, y = [], []
data_len = data.shape[0]
for i in range(sequence_length, data_len):
x.append(data[i-sequence_length:i,:]) #contains sequence_length values 0-sequence_length * columsn
y.append(data[i, index_Close]) #contains the prediction values for validation, for single-step prediction
# Convert the x and y to numpy arrays
x = np.array(x)
y = np.array(y)
return x, y
# Generate training data and test data
x_train, y_train = partition_dataset(sequence_length, train_data)
x_test, y_test = partition_dataset(sequence_length, test_data)
# Print the shapes: the result is: (rows, training_sequence, features) (prediction value, )
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
# Validate that the prediction value and the input match up
# The last close price of the second input sample should equal the first prediction value
print(x_train[1][sequence_length-1][index_Close])
print(y_train[0])(2474, 50, 5) (2474,)
(630, 50, 5) (630,)
0.02049456793614579
0.02049456793614579Step #5 Train the Multivariate Prediction Model
Once we have the data prepared and ready, we can train our model. The architecture of our neural network consists of the following four layers:
- An LSTM layer, which takes our mini-batches as input and returns the whole sequence
- Another LSTM layer that takes the sequence from the previous layer but only returns five values
- Dense layer with five neurons
- A final dense layer that outputs the predicted value
The number of neurons in the first layer must equal the size of a minibatch of the input data. Each minibatch in our dataset consists of a matrix with 50 steps and six features. Thus, the input layer of our recurrent neural network consists of 300 neurons. Keeping this architecture in mind is essential because, later, we need to bring the data into the same shape when we want to predict a new dataset. Running the code below creates the model architecture and compiles the model.
# Configure the neural network model
model = Sequential()
# Model with n_neurons = inputshape Timestamps, each with x_train.shape[2] variables
n_neurons = x_train.shape[1] * x_train.shape[2]
print(n_neurons, x_train.shape[1], x_train.shape[2])
model.add(LSTM(n_neurons, return_sequences=True, input_shape=(x_train.shape[1], x_train.shape[2])))
model.add(LSTM(n_neurons, return_sequences=False))
model.add(Dense(5))
model.add(Dense(1))
# Compile the model
model.compile(optimizer='adam', loss='mse')Running the code below starts the training process.
# Training the model
epochs = 50
batch_size = 16
early_stop = EarlyStopping(monitor='loss', patience=5, verbose=1)
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_test, y_test)
)
#callbacks=[early_stop])Output exceeds the size limit. Open the full output data in a text editor
Epoch 1/50
155/155 [==============================] - 6s 19ms/step - loss: 6.7374e-04 - val_loss: 0.0011
Epoch 2/50
155/155 [==============================] - 2s 13ms/step - loss: 6.6207e-05 - val_loss: 8.4700e-04
Epoch 3/50
155/155 [==============================] - 2s 14ms/step - loss: 5.0667e-05 - val_loss: 6.6467e-04
Epoch 4/50
155/155 [==============================] - 2s 14ms/step - loss: 5.8446e-05 - val_loss: 6.8575e-04
Epoch 5/50
155/155 [==============================] - 2s 14ms/step - loss: 4.8430e-05 - val_loss: 8.4892e-04
Epoch 6/50
155/155 [==============================] - 2s 14ms/step - loss: 7.1283e-05 - val_loss: 8.2255e-04
Epoch 7/50
155/155 [==============================] - 2s 15ms/step - loss: 6.0554e-05 - val_loss: 8.0583e-04
Epoch 8/50
155/155 [==============================] - 2s 15ms/step - loss: 5.5977e-05 - val_loss: 4.5830e-04
Epoch 9/50
155/155 [==============================] - 2s 15ms/step - loss: 4.2453e-05 - val_loss: 6.1866e-04
Epoch 10/50
155/155 [==============================] - 2s 14ms/step - loss: 3.5722e-05 - val_loss: 4.5288e-04
Epoch 11/50
155/155 [==============================] - 2s 14ms/step - loss: 4.1409e-05 - val_loss: 8.5975e-04
Epoch 12/50
155/155 [==============================] - 3s 18ms/step - loss: 7.0007e-05 - val_loss: 5.0300e-04
Epoch 13/50
...
Epoch 49/50
155/155 [==============================] - 2s 13ms/step - loss: 2.7064e-05 - val_loss: 2.8202e-04
Epoch 50/50
155/155 [==============================] - 2s 13ms/step - loss: 2.9009e-05 - val_loss: 2.5486e-04Let’s take a quick look at the loss curve.
# Plot training & validation loss values
fig, ax = plt.subplots(figsize=(16, 5), sharex=True)
sns.lineplot(data=history.history["loss"])
plt.title("Model loss")
plt.ylabel("Loss")
plt.xlabel("Epoch")
ax.xaxis.set_major_locator(plt.MaxNLocator(epochs))
plt.legend(["Train", "Test"], loc="upper left")
plt.grid()
plt.show()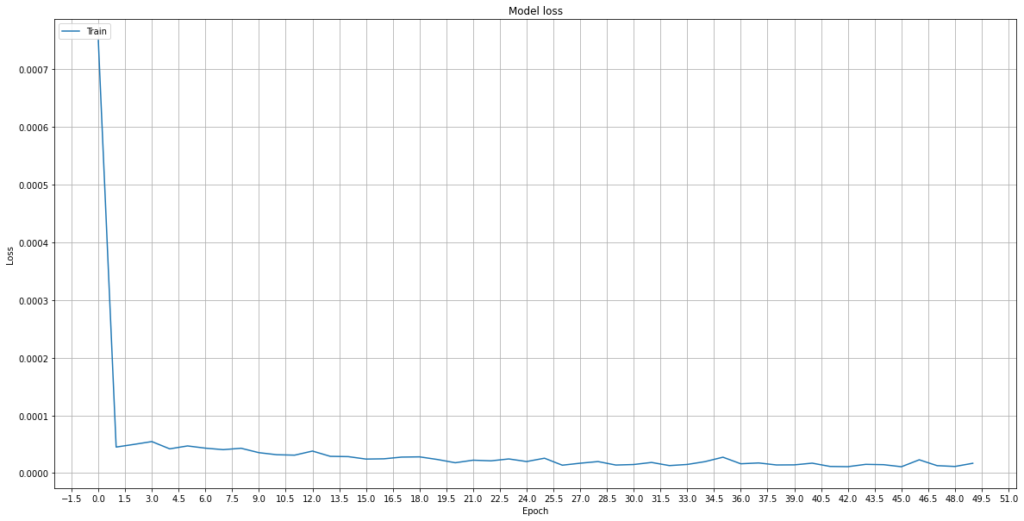
The loss drops quickly to a lower plateau, which signals that the model has improved throughout the training process.
Step #6 Evaluate Model Performance
Once we have trained the neural network regression model, we want to measure its performance. As mentioned in section 3, we first have to reverse the scaling of the predictions. Afterward, we calculate different error metrics, MAE, MAPE, and MDAPE. Then we will compare the predictions in a line plot with the actual values. For more information on measuring the performance of regression models, see this relataly article.
# Get the predicted values
y_pred_scaled = model.predict(x_test)
# Unscale the predicted values
y_pred = scaler_pred.inverse_transform(y_pred_scaled)
y_test_unscaled = scaler_pred.inverse_transform(y_test.reshape(-1, 1))
# Mean Absolute Error (MAE)
MAE = mean_absolute_error(y_test_unscaled, y_pred)
print(f'Median Absolute Error (MAE): {np.round(MAE, 2)}')
# Mean Absolute Percentage Error (MAPE)
MAPE = np.mean((np.abs(np.subtract(y_test_unscaled, y_pred)/ y_test_unscaled))) * 100
print(f'Mean Absolute Percentage Error (MAPE): {np.round(MAPE, 2)} %')
# Median Absolute Percentage Error (MDAPE)
MDAPE = np.median((np.abs(np.subtract(y_test_unscaled, y_pred)/ y_test_unscaled)) ) * 100
print(f'Median Absolute Percentage Error (MDAPE): {np.round(MDAPE, 2)} %')Median Absolute Error (MAE): 175.28
Mean Absolute Percentage Error (MAPE): 1.48 %
Median Absolute Percentage Error (MDAPE): 1.16 %The MAPE is 22.15, which means that the mean of our predictions deviates from the actual values by 3.12%. The MDAPE is 2.88 % and a bit lower than the mean, thus indicating there are some outliers among the prediction errors. 50% of the predictions deviate by more than 2.88%, and 50% differ by less than 2.88% from the actual values.
Next, we create a line plot showing the forecast and compare it to the actual values. Adding a bar plot to the chart helps highlight the deviations of the predictions from the actual values. Running the code below creates the line plot.
# The date from which on the date is displayed
display_start_date = "2019-01-01"
# Add the difference between the valid and predicted prices
train = pd.DataFrame(data_filtered_ext['Close'][:train_data_len + 1]).rename(columns={'Close': 'y_train'})
valid = pd.DataFrame(data_filtered_ext['Close'][train_data_len:]).rename(columns={'Close': 'y_test'})
valid.insert(1, "y_pred", y_pred, True)
valid.insert(1, "residuals", valid["y_pred"] - valid["y_test"], True)
df_union = pd.concat([train, valid])
# Zoom in to a closer timeframe
df_union_zoom = df_union[df_union.index > display_start_date]
# Create the lineplot
fig, ax1 = plt.subplots(figsize=(16, 8))
plt.title("y_pred vs y_test")
plt.ylabel(stockname, fontsize=18)
sns.set_palette(["#090364", "#1960EF", "#EF5919"])
sns.lineplot(data=df_union_zoom[['y_pred', 'y_train', 'y_test']], linewidth=1.0, dashes=False, ax=ax1)
# Create the bar plot with the differences
df_sub = ["#2BC97A" if x > 0 else "#C92B2B" for x in df_union_zoom["residuals"].dropna()]
ax1.bar(height=df_union_zoom['residuals'].dropna(), x=df_union_zoom['residuals'].dropna().index, width=3, label='residuals', color=df_sub)
plt.legend()
plt.show()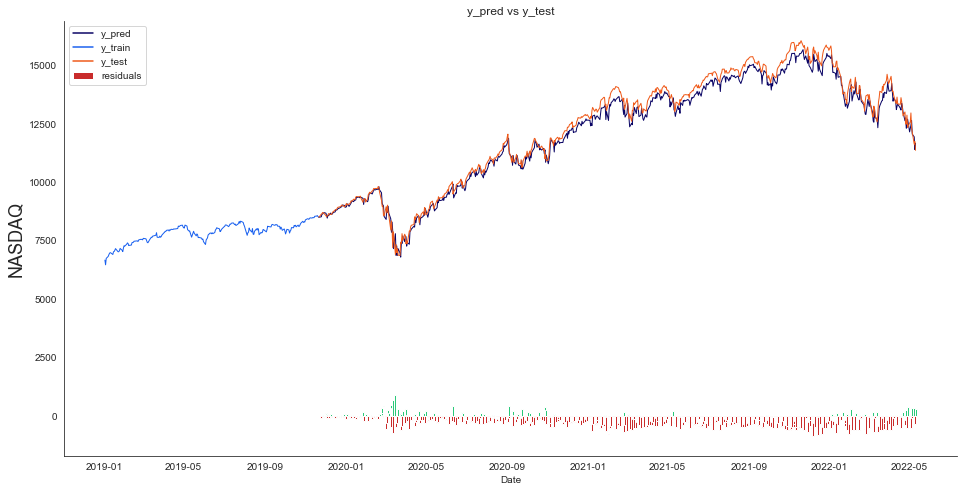
The line plot shows that the forecast is close to the actual values but partially deviates from it. The deviations between actual values and predictions are called residuals. For our mode, they seem to be most significant during periods of increased market volatility and least during periods of steady market movement, which makes sense because sudden movements are generally more difficult to predict.
Step #7 Predict the Next Day’s Price
After training the neural network, we want to forecast the stock market for the next day. For this purpose, we extract a new dataset from the Yahoo-Finance API and preprocess it as we did for model training.
We trained our model with mini-batches of 50-steps and six features. Thus, we must also provide the model with 50-steps when making the forecast. As before, we transform the data into the shape of 1 x 50 x 6, whereby the last figure is the number of feature columns. After generating the forecast, we unscale the stock market predictions back to the original range of values.
df_temp = df[-sequence_length:]
new_df = df_temp.filter(FEATURES)
N = sequence_length
# Get the last N day closing price values and scale the data to be values between 0 and 1
last_N_days = new_df[-sequence_length:].values
last_N_days_scaled = scaler.transform(last_N_days)
# Create an empty list and Append past N days
X_test_new = []
X_test_new.append(last_N_days_scaled)
# Convert the X_test data set to a numpy array and reshape the data
pred_price_scaled = model.predict(np.array(X_test_new))
pred_price_unscaled = scaler_pred.inverse_transform(pred_price_scaled.reshape(-1, 1))
# Print last price and predicted price for the next day
price_today = np.round(new_df['Close'][-1], 2)
predicted_price = np.round(pred_price_unscaled.ravel()[0], 2)
change_percent = np.round(100 - (price_today * 100)/predicted_price, 2)
plus = '+'; minus = ''
print(f'The close price for {stockname} at {end_date} was {price_today}')
print(f'The predicted close price is {predicted_price} ({plus if change_percent > 0 else minus}{change_percent}%)')The close price for NASDAQ on 2021-06-27 was 14360.39. The predicted closing price is 14232.8095703125 (-0.9%)
Summary
This tutorial has shown multivariate time series modeling for stock market prediction in Python. We trained a neural network regression model for predicting the NASDAQ index. Before training our model, we performed several steps to prepare the data. The steps included splitting the data and scaling them. In addition, we created and tested various new features from the original time series data to account for the multivariate modeling approach. You now have the knowledge and code to conduct further experiments with the features of your choice.
Multivariate time series forecasting is a complex topic. You might want to take the time to retrace the different steps. Especially the transformation of the data can be challenging. The best way to learn is to practice. Therefore I encourage you to develop more time series models and experiment with other data sources.
Another interesting approach to stock market prediction uses candlestick images and convolutional neural networks. If this topic interests you, check out the following article: Deep reinforcement learning stock market trading, utilizing a CNN with candlestick images
I am always trying to learn and improve. If you want to give feedback or have remarks, feel free to share them in the comments.

Stockmarket forecasting with a neural network is about identifying meaningful patterns. Be aware that there is no guarantee that these patterns are present in the data. Image created with Midjourney.
Sources and Further Reading
- Charu C. Aggarwal (2018) Neural Networks and Deep Learning
- Jansen (2020) Machine Learning for Algorithmic Trading: Predictive models to extract signals from market and alternative data for systematic trading strategies with Python
- Aurélien Géron (2019) Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems
- David Forsyth (2019) Applied Machine Learning Springer
- Andriy Burkov (2020) Machine Learning Engineering
The links above to Amazon are affiliate links. By buying through these links, you support the Relataly.com blog and help to cover the hosting costs. Using the links does not affect the price.
- Stock Market Forecasting using Univariate Models and Python
- Multi-step Time Series Forecasting with Python: Step-by-Step Guide
- Stock Market Prediction – Adjusting Time Series Prediction Intervals
- Evaluating Time Series Forecasting Models with Python
- Georg Box
- Python 3
- Anaconda environment
- pandas
- NumPy
- math
- matplotlib
- Keras
- Tensorflow
- sci-kit-learn
- pandas-DataReader
- NASDAQ
- yahoo.finance.com
- Deep reinforcement learning stock market trading, utilizing a CNN with candlestick images




17 Commentsarchived from the original site