Stock Market Prediction - Adjusting Time Series Prediction Intervals in Python

Get ready to level up your time-series forecasting game! In this tutorial, we’re going to take things up a notch by showing you how to adjust prediction intervals using Keras recurrent neural networks and Python.
Now, you may remember our previous article on stock market forecasting where we made a forecast for the S&P500 stock market index using a prediction interval of just one day. However, other time-series prediction problems may require us to look further ahead - maybe several days, weeks, or even months. Fear not! We’ve got you covered.
By tweaking our data preparation and model architecture, we can modify the prediction interval and create a single-step forecast for a longer time frame. In this article, we’re going to show you exactly how to do that.
First, we’ll give you a quick rundown of different methods for adjusting the time series prediction interval. Then, we’ll dive into the practical stuff. We’ll use Python to train a simple neural network on stock market data and validate its performance. Once we’re happy with the model, we’ll prepare the data in a way that allows us to forecast a single but more extended step into the future.
Ready to take your time-series forecasting to the next level? Then let’s get started!
Disclaimer
This article does not constitute financial advice. Stock markets can be very volatile and are generally difficult to predict. Predictive models and other forms of analytics applied in this article only serve the purpose of illustrating machine learning use cases.

Time Series Analysis
Ways of Adjusting Prediction Intervals
When forecasting one step, the prediction interval is the point in time for which a prediction model will simulate the next value. There are three different ways to change the prediction interval:
- Multi-Step Rolling Forecasting: Another way is to train the model on its output. We do this by maintaining the predictions and reusing them as input in the subsequent training run. In this way, the projections range one-time step further ahead with each iteration. After seven iterations, based on daily input time steps, the model will have provided the output for a weekly prediction. We have covered this rolling forecasting approach in a separate tutorial.
- Deep Multi-Output Forecasting: A third option is to create a multi-output model that provides an entire series of predictions with multiple timesteps. We have covered this multi-output forecasting approach in a separate tutorial.
- Single-step forecasting with bigger timesteps: In a single-stage forecasting approach, the input data defines the length of a time step. Changing the size of the input steps will change the output steps to the same extent. For example, a model that uses daily prices as input data will also provide day-to-day forecasts. We will cover this forecasting approach in the following section.
Predicting the Price of the S&P500 One Week Ahead
Let’s begin with the hands-on part. In this part, we will use Python to create a single-step forecasting model with more extended timesteps. Our model will make projections that reach one week ahead. For this purpose, we reuse most of the code from the previous article on univariate single-step daily forecasting. So we won’t go into all the details and will only speak about the areas in which we must adjust the code. Changes are necessary to data preparation and model architecture.
In the following, we develop a single-variate neural network model that forecasts the S&P500 stock market index. The code is available on the GitHub repository.
Prerequisites
Before starting the coding part, make sure that you have set up your Python 3 environment and required packages. If you don’t have an environment, you can follow these steps to set up the Anaconda environment.
Also, make sure you install all required packages. In this tutorial, we will be working with the following standard packages:
In addition, we will be using Keras(2.0 or higher) with Tensorflow backend, the machine learning library sci-kit-learn, and pandas DataReader to interact with the yahoo finance API.
You can install packages using console commands:
- pip install
- conda install
(if you are using the anaconda packet manager)
Step #1 Load the Data
In the following, we will modify the prediction interval of the neural network model we developed in a previous post. As a result, the model will generate predictions for the market price of the S&P500 Index that range one week ahead.
As before, we start loading the stock market data via an API.
# A tutorial for this file is available at www.relataly.com
import math # Fundamental package for scientific computing with Python
import numpy as np # Additional functions for analysing and manipulating data
import pandas as pd # Date Functions
from datetime import date, timedelta # This function adds plotting functions for calender dates
from pandas.plotting import register_matplotlib_converters # Important package for visualization - we use this to plot the market data
import matplotlib.pyplot as plt # Formatting dates
import matplotlib.dates as mdates # Packages for measuring model performance / errors
from sklearn.metrics import mean_absolute_error, mean_squared_error # Tools for predictive data analysis. We will use the MinMaxScaler to normalize the price data
from sklearn.preprocessing import MinMaxScaler # Deep learning library, used for neural networks
from tensorflow.keras.models import Sequential # Deep learning classes for recurrent and regular densely-connected layers
from tensorflow.keras.layers import LSTM, Dense
from tensorflow.keras.callbacks import EarlyStopping
import tensorflow as tf
import seaborn as sns
sns.set_style('white', { 'axes.spines.right': False, 'axes.spines.top': False})
# check the tensorflow version and the number of available GPUs
print('Tensorflow Version: ' + tf.__version__)
physical_devices = tf.config.list_physical_devices('GPU')
print("Num GPUs:", len(physical_devices))
# Setting the timeframe for the data extraction
end_date = date.today().strftime("%Y-%m-%d")
start_date = '2010-01-01'
# Getting S&P500 quotes
stockname = 'S&P500'
symbol = '^GSPC'
# You can either use webreader or yfinance to load the data from yahoo finance
# import pandas_datareader as webreader
# df = webreader.DataReader(symbol, start=start_date, end=end_date, data_source="yahoo")
import yfinance as yf #Alternative package if webreader does not work: pip install yfinance
df = yf.download(symbol, start=start_date, end=end_date)
df.head(5)Tensorflow Version: 2.5.0
Num GPUs: 0
[*********************100%***********************] 1 of 1 completed
Open High Low Close Adj Close Volume
Date
2009-12-31 1126.599976 1127.640015 1114.810059 1115.099976 1115.099976 2076990000
2010-01-04 1116.560059 1133.869995 1116.560059 1132.989990 1132.989990 3991400000
2010-01-05 1132.660034 1136.630005 1129.660034 1136.520020 1136.520020 2491020000
2010-01-06 1135.709961 1139.189941 1133.949951 1137.140015 1137.140015 4972660000
2010-01-07 1136.270020 1142.459961 1131.319946 1141.689941 1141.689941 5270680000Step #2 Adjusting the Shape of the Input Data and Exploration
We have a DataFrame that contains the daily price quotes for the S&P 500. Next, we prepare the data to include the weekly price quotes. If we want our model to provide weekly price predictions, we need to change the data so that the input contains weekly price quotes. A simple way to achieve this is to iterate through the rows and only keep every 7th row.
# Changing the data structure to a dataframe with weekly price quotes
df["index1"] = range(1, len(df) + 1)
rownumber = df.shape[0]
lst = list(range(rownumber))
list_of_relevant_numbers = lst[0::7]
df_weekly = df[df["index1"].isin(list_of_relevant_numbers)]
df_weekly.head(5) Open High Low Close Adj Close Volume index1
Date
2010-01-11 1145.959961 1149.739990 1142.020020 1146.979980 1146.979980 4255780000 7
2010-01-21 1138.680054 1141.579956 1114.839966 1116.479980 1116.479980 6874290000 14
2010-02-01 1073.890015 1089.380005 1073.890015 1089.189941 1089.189941 4077610000 21
2010-02-10 1069.680054 1073.670044 1059.339966 1068.130005 1068.130005 4251450000 28
2010-02-22 1110.000000 1112.290039 1105.380005 1108.010010 1108.010010 3814440000 35After this, we quickly create a line plot to validate that everything looks as expected.
# Creating a Lineplot
years = mdates.YearLocator()
fig, ax1 = plt.subplots(figsize=(16, 6))
ax1.xaxis.set_major_locator(years)
ax1.legend([stockname], fontsize=12)
plt.title(stockname + ' from '+ start_date + ' to ' + end_date)
sns.lineplot(data=df['Close'], label=stockname, linewidth=1.0)
plt.ylabel('S&P500 Points')
plt.show() Open High Low Close Adj Close Volume index1
Date
2010-01-11 1145.959961 1149.739990 1142.020020 1146.979980 1146.979980 4255780000 7
2010-01-21 1138.680054 1141.579956 1114.839966 1116.479980 1116.479980 6874290000 14
2010-02-01 1073.890015 1089.380005 1073.890015 1089.189941 1089.189941 4077610000 21
2010-02-10 1069.680054 1073.670044 1059.339966 1068.130005 1068.130005 4251450000 28
2010-02-22 1110.000000 1112.290039 1105.380005 1108.010010 1108.010010 3814440000 35Step #3 Preprocess the Data
Before we can train the neural network, we first need to define the shape of the training data. We use weekly price quotes and define an input_sequence_length of 50 weeks.
# Feature Selection - Only Close Data
train_df = df.filter(['Close'])
data_unscaled = df.values
# Transform features by scaling each feature to a range between 0 and 1
mmscaler = MinMaxScaler(feature_range=(0, 1))
np_data = mmscaler.fit_transform(data_unscaled)
# Creating a separate scaler that works on a single column for scaling predictions
scaler_pred = MinMaxScaler()
df_Close = pd.DataFrame(df['Close'])
np_Close_scaled = scaler_pred.fit_transform(df_Close)
# Set the sequence length - this is the timeframe used to make a single prediction
sequence_length = 25
# Prediction Index
index_Close = train_df.columns.get_loc("Close")
# Split the training data into train and train data sets
# As a first step, we get the number of rows to train the model on 80% of the data
train_data_length = math.ceil(np_data.shape[0] * 0.8)
# Create the training and test data
train_data = np_data[0:train_data_length, :]
test_data = np_data[train_data_length - sequence_length:, :]
# The RNN needs data with the format of [samples, time steps, features]
# Here, we create N samples, sequence_length time steps per sample, and 6 features
def partition_dataset(sequence_length, train_df):
x, y = [], []
data_len = train_df.shape[0]
for i in range(sequence_length, data_len):
x.append(train_df[i-sequence_length:i,:]) #contains sequence_length values 0-sequence_length * columsn
y.append(train_df[i, index_Close]) #contains the prediction values for validation (3rd column = Close), for single-step prediction
# Convert the x and y to numpy arrays
x = np.array(x)
y = np.array(y)
return x, y
# Generate training data and test data
x_train, y_train = partition_dataset(sequence_length, train_data)
x_test, y_test = partition_dataset(sequence_length, test_data)
# Print the shapes: the result is: (rows, training_sequence, features) (prediction value, )
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
# Validate that the prediction value and the input match up
# The last close price of the second input sample should equal the first prediction value
print(x_test[1][sequence_length-1][index_Close])
print(y_test[0])(2465, 25, 7) (2465,)
(622, 25, 7) (622,)
0.5509444640253316
0.5509444640253316Step #4 Building a Time Series Prediction Model
The first layer of neurons in our neural network needs to fit the input values from the data. Therefore, we need 50 neurons - one for each input price quote.
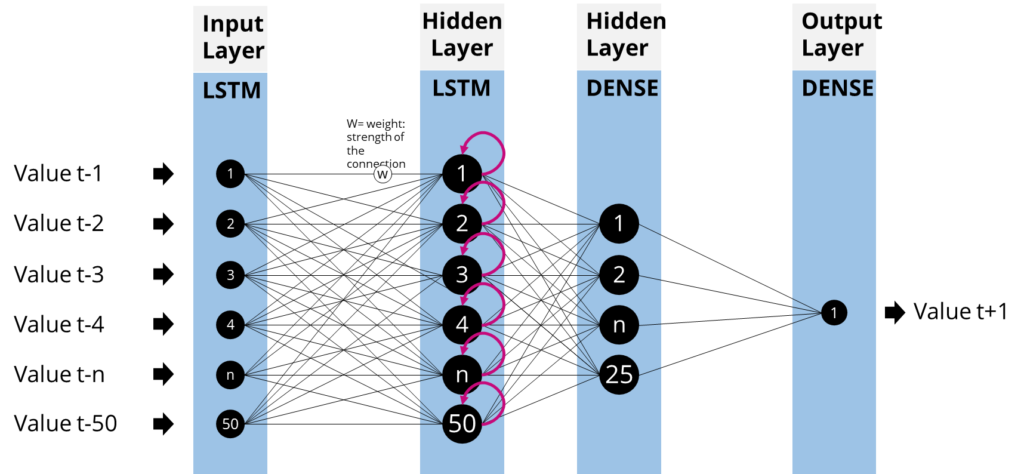
The model architecture of the recurrent neural network
We use the following input arguments for the model fit:
- x_train: Vector, matrix, or array of training data. It can also be a list (as in our case) if the model has multiple inputs.
- y_train: Vector, matrix, or array of target data. This is the labeled data the model tries to predict; in other words, these are the results of x_train.
- Epochs: The integer value defines how often the model goes through the training set.
- Batch size: Integer value that defines the number of samples that will be propagated through the network. After each propagation, the network adjusts the weights of the nodes in each layer.
# Configure the neural network model
model = Sequential()
# Model with n_neurons Neurons
n_neurons = x_train.shape[1] * x_train.shape[2]
print(n_neurons, x_train.shape[1], x_train.shape[2])
model.add(LSTM(n_neurons, return_sequences=True, input_shape=(x_train.shape[1], x_train.shape[2])))
model.add(LSTM(n_neurons, return_sequences=False))
model.add(Dense(25, activation="relu"))
model.add(Dense(1))
# Compile the model
model.compile(optimizer="adam", loss="mean_squared_error")
# Training the model
epochs = 10
early_stop = EarlyStopping(monitor='loss', patience=2, verbose=1)
history = model.fit(x_train, y_train,
batch_size=16,
epochs=epochs,
callbacks=[early_stop])Epoch 1/10
155/155 [==============================] - 7s 25ms/step - loss: 8.2791e-04
Epoch 2/10
155/155 [==============================] - 4s 24ms/step - loss: 1.3465e-04
Epoch 3/10
155/155 [==============================] - 4s 24ms/step - loss: 1.0998e-04
Epoch 4/10
155/155 [==============================] - 4s 25ms/step - loss: 1.0241e-04
Epoch 5/10
155/155 [==============================] - 4s 24ms/step - loss: 7.4277e-05
Epoch 6/10
155/155 [==============================] - 4s 24ms/step - loss: 6.5786e-05
Epoch 7/10
155/155 [==============================] - 4s 24ms/step - loss: 6.8482e-05
Epoch 8/10
155/155 [==============================] - 4s 24ms/step - loss: 5.0326e-05
Epoch 9/10
155/155 [==============================] - 4s 24ms/step - loss: 4.8574e-05
Epoch 10/10
155/155 [==============================] - 4s 25ms/step - loss: 4.1287e-05Step #5 Evaluate Model Performance
Next, we validate the model by calculating our predictions’ mean-squared and root-mean-squared errors. However, in time series forecasting metrics can be misleading. It is good to double-check model results using illustrations. Therefore, we plot the input sequences and the forecast to see if our model can continue the time series in a plausible way.
# Get the predicted values
y_pred_scaled = model.predict(x_test)
y_pred = scaler_pred.inverse_transform(y_pred_scaled)
y_test_unscaled = scaler_pred.inverse_transform(y_test.reshape(-1, 1))
# Mean Absolute Error (MAE)
MAE = mean_absolute_error(y_test_unscaled, y_pred)
print(f'Median Absolute Error (MAE): {np.round(MAE, 2)}')
# Mean Absolute Percentage Error (MAPE)
MAPE = np.mean((np.abs(np.subtract(y_test_unscaled, y_pred)/ y_test_unscaled))) * 100
print(f'Mean Absolute Percentage Error (MAPE): {np.round(MAPE, 2)} %')
# Median Absolute Percentage Error (MDAPE)
MDAPE = np.median((np.abs(np.subtract(y_test_unscaled, y_pred)/ y_test_unscaled)) ) * 100
print(f'Median Absolute Percentage Error (MDAPE): {np.round(MDAPE, 2)} %')
# The date from which on the date is displayed
display_start_date = "2018-01-01"
# Add the difference between the valid and predicted prices
train = pd.DataFrame(train_df[:train_data_length + 1]).rename(columns={'Close': 'x_train'})
valid = pd.DataFrame(train_df[train_data_length:]).rename(columns={'Close': 'y_test'})
valid.insert(1, "y_pred", y_pred, True)
valid.insert(1, "residuals", valid["y_pred"] - valid["y_test"], True)
df_union = pd.concat([train, valid])
# Zoom in to a closer timeframe
df_union_zoom = df_union[df_union.index > display_start_date]
# Create the lineplot
fig, ax1 = plt.subplots(figsize=(16, 8))
plt.title("Predictions vs Ground Truth")
plt.ylabel(stockname, fontsize=18)
sns.despine();
sns.lineplot(data=df_union_zoom, linewidth=1.0, palette='CMRmap', ax=ax1)
plt.show()Median Absolute Error (MAE): 42.7
Mean Absolute Percentage Error (MAPE): 1.16 %
Median Absolute Percentage Error (MDAPE): 0.92 %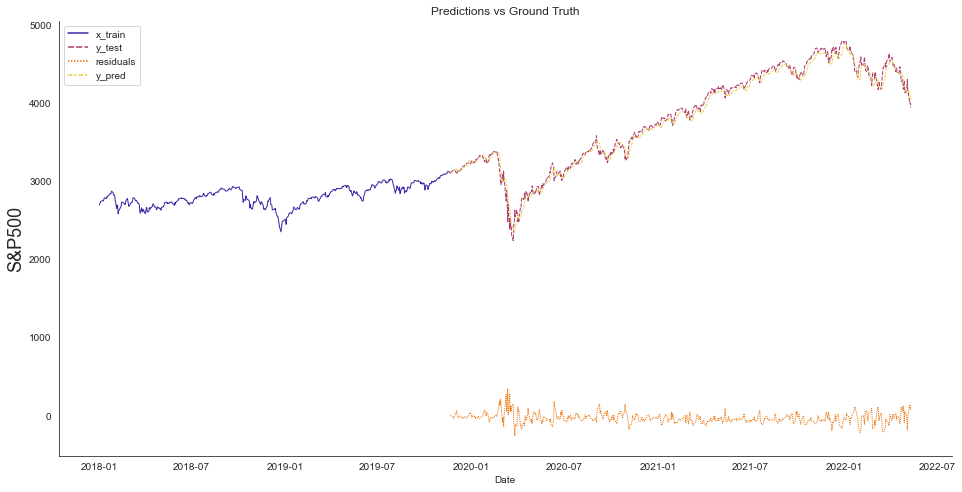
At the bottom, we can see the differences between predictions and valid data. Positive values signal that the projections were too optimistic. Negative values mean that the predictions were too pessimistic and that the actual value turned out to be higher than the prediction.
Step #6 Predicting for the Next Week
What can be more satisfying than to see a newly trained model at work? Let’s use our new model to predict next week’s price for the S&P500. We will create a fresh input_sequence with prices from the past N days. Then we scale this input sequence and include it as input in our call to the model.predict() function.
# Get fresh data until today and create a new dataframe with only the price data
new_df = df
N = sequence_length
# Get the last N steps closing price values and scale the data to be values between 0 and 1
last_N_steps = new_df[-sequence_length:].values
last_N_steps_scaled = mmscaler.transform(last_N_steps)
# Create an empty list and Append past N steps
X_test_new = []
X_test_new.append(last_N_steps_scaled)
# Convert the X_test data set to a numpy array and reshape the data
pred_price_scaled = model.predict(np.array(X_test_new))
pred_price_unscaled = scaler_pred.inverse_transform(pred_price_scaled.reshape(-1, 1))
# Print last price and predicted price for the next week
price_today = np.round(new_df['Close'][-1], 2)
predicted_price = np.round(pred_price_unscaled.ravel()[0], 2)
change_percent = np.round(100 - (price_today * 100)/predicted_price, 2)
plus = '+'; minus = ''
print(f'The close price for {stockname} at {end_date} was {price_today}')
print(f'The predicted close price is {predicted_price} ({plus if change_percent > 0 else minus}{change_percent}%)')The close price for S&P500 at 2022-05-11 was 4001.05
The predicted close price is 4046.300048828125 (+1.12%)So for the 9th of April 2020, the model predicts that the S&P500 will close at:
4046.300048828125
Considering today’s (2nd of April 2020) price is 2528 points, our model expects the S&P to gain roughly 124 points in the coming seven days. Of course, this is by no means financial advice. As we have seen before, our model is often wrong.
Summary
This article has shown how to adjust the prediction intervals for a time series forecasting model. We have created a neural network that predicts the price of the S&P500 one week in advance. Finally, we trained and validated the model and made a forecast for the next week.
Varying the input shape is a quick approach to changing the forecasting time steps. However, increasing the length of the time steps also reduces the amount of data we can use for training and testing. In our case, we still have enough data available. But in other cases, where less information is available, this can become a problem. The preferred method is to use a rolling forecast approach or create a multi-output forecast in such a case.
I hope this article was helpful. Should you have questions or remarks, let me know in the comments.
Sources and Further Readings
The links above to Amazon are affiliate links. By buying through these links, you support the Relataly.com blog and help to cover the hosting costs. Using the links does not affect the price.




2 Commentsarchived from the original site