Customer Churn Prediction - Understanding Models with Feature Permutation Importance using Python
Customer retention is a prime objective for service companies, and understanding the patterns that lead to customer churn can be the key to maintaining long-lasting client relationships. Businesses incur significant costs when customers discontinue their services, hence it’s vital to identify potential churn risks and take preemptive actions to retain these customers. Machine Learning models can be instrumental in identifying these patterns and providing valuable insights into customer behavior.
An intriguing technique, Permutation Feature Importance, allows us to discern the significance of different features of our machine learning model, thereby shedding light on their influence on customer churn. This tutorial guides you through the intricacies of this technique and its implementation.
The structure of this tutorial is as follows:
- We begin by discussing the business problem of customer churn and its implications.
- We introduce the concept of Permutation Feature Importance, a powerful tool to identify essential features in our machine learning model.
- We transition into the hands-on coding segment, where we build a churn prediction model using Python.
- Our model undergoes a classification process and hyperparameter tuning to select the most effective parameters.
- Utilizing the trained model, we predict the churn probabilities for a test set of customers.
- Finally, we create a feature ranking based on their impact on the model’s performance.
By employing permutation feature importance, this tutorial offers a deep-dive into the correlation between input variables and model predictions, providing actionable insights for effective customer churn management.
Also:
- Using Fairlearn to Build Fair Machine Learning Models with Python: Step-by-Step Towards More Responsible AI
- How to Use Hierarchical Clustering For Customer Segmentation in Python
Customer churn prediction is a compelling use case for machine learning. It is particularly effective when combined with feature permutation importance.
What is Churn Prediction?
A company’s effort to persuade a new customer to sign a contract is many times higher than the costs incurred in retaining existing customers. According to industry experts, winning a new customer is four times more expensive than keeping an existing one. Providers that can identify churn candidates and manage to retain them can significantly reduce costs.
A crucial point is whether the provider succeeds in getting the churn candidates to stay. Sometimes it may be enough to contact the churn candidate and inquire about customer satisfaction. In other cases, this may not be enough, and the provider needs to increase the service value, for example, by offering free services or a discount. However, actions should be well thought out, as they can also negatively affect. For instance, if a customer hardly ever uses his contract, a call from the provider may even increase the desire to cancel the contract. Machine learning can help assess cases individually and identify the optimal anti-churn action.
About Permutation Feature Importance
Feature importance is a helpful technique for understanding the contribution of input variables (features) to a predictive model. The results from this technique can be as valuable as the predictions themselves, as they can help us understand the business context better. For example, let’s say we have trained a model that predicts which of our customers will likely churn. Wouldn’t it be interesting to know why specific customers are more likely to churn than others? Permutation feature importance can help us answer this question by providing us with a ranking of the input variables in our model by their usefulness. The order can validate assumptions about the business context and uncover causal relations in the data.
Compared to neural networks, one of the most significant advantages of traditional prediction models, such as a decision tree, is their interpretability. Neural networks are black boxes because it is tough to understand the relationship between input and model predictions. In traditional models, on the other hand, we can calculate the meaning of the features and use it to interpret the model and optimize its performance, for example, by removing features from the model that are not important. We, therefore, start with a simple model first and move on to more complex models once we understand the data.
Implementing a Customer Churn Prediction Model in Python
In the following, we will implement a customer churn prediction model. We will train a decision forest model on a data set from Kaggle and optimize it using grid search. The data contains customer-level information for a telecom provider and a binary prediction label of which customers canceled their contracts and did not. Finally, we will calculate the feature importance to understand how the model works.
The code is available on the GitHub repository.
Prerequisites
Before starting the coding part, make sure that you have set up your Python 3 environment and required packages. If you don’t have an environment, you can follow this tutorial to set up the Anaconda environment.
Make sure you install all required packages. In this tutorial, we will be working with the following packages:
- Pandas
- NumPy
- Matplotlib
- Seaborn
In addition, we will be using Keras(2.0 or higher) with Tensorflow backend and the machine learning library Scikit-learn.
You can install packages using console commands:
- pip install
- conda install
(if you are using the anaconda packet manager)
Step #1 Loading the Customer Churn Data
We begin by loading a customer churn dataset from Kaggle. If you work with the Kaggle Python environment, you can directly save the dataset into your Kaggle project. After completing the download, put the dataset under the file path of your choice, but don’t forget to adjust the file path variable in the code.
The dataset contains 3333 records and the following attributes.
- Churn: The prediction label: 1 if the customer canceled service, 0 if not.
- AccountWeeks: number of weeks the customer has had an active account
- ContractRenewal: 1 if customer recently renewed contract, 0 if not
- DataPlan: 1 if the customer has a data plan, 0 if not
- DataUsage: gigabytes of monthly data usage
- CustServCalls: number of calls into customer service
- DayMins: average daytime minutes per month
- DayCalls: average number of daytime calls
- MonthlyCharge: average monthly bill
- OverageFee: The most considerable overage fee in the last 12 months
The following code will load the data from your local folder into your anaconda Python project:
import numpy as np
import pandas as pd
import math
from pandas.plotting import register_matplotlib_converters
import matplotlib.pyplot as plt
import matplotlib.colors as mcolors
import matplotlib.dates as mdates
from sklearn.metrics import confusion_matrix, classification_report
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.inspection import permutation_importance
import seaborn as sns
# set file path
filepath = "data/Churn-prediction/"
# Load train and test datasets
train_df = pd.read_csv(filepath + 'telecom_churn.csv')
train_df.head() Churn AccountWeeks ContractRenewal DataPlan DataUsage CustServCalls DayMins DayCalls MonthlyCharge OverageFee RoamMins
0 0 128 1 1 2.7 1 265.1 110 89.0 9.87 10.0
1 0 107 1 1 3.7 1 161.6 123 82.0 9.78 13.7
2 0 137 1 0 0.0 0 243.4 114 52.0 6.06 12.2
3 0 84 0 0 0.0 2 299.4 71 57.0 3.10 6.6
4 0 75 0 0 0.0 3 166.7 113 41.0 7.42 10.1Step #2 Exploring the Data
Before we begin with the preprocessing, we will quickly explore the data. For this purpose, we will create histograms for the different attributes in our data.
# # Create histograms for feature columns separated by prediction label value
df_plot = train_df.copy()
# class_columnname = 'Churn'
sns.pairplot(df_plot, hue="Churn", height=2.5, palette='muted')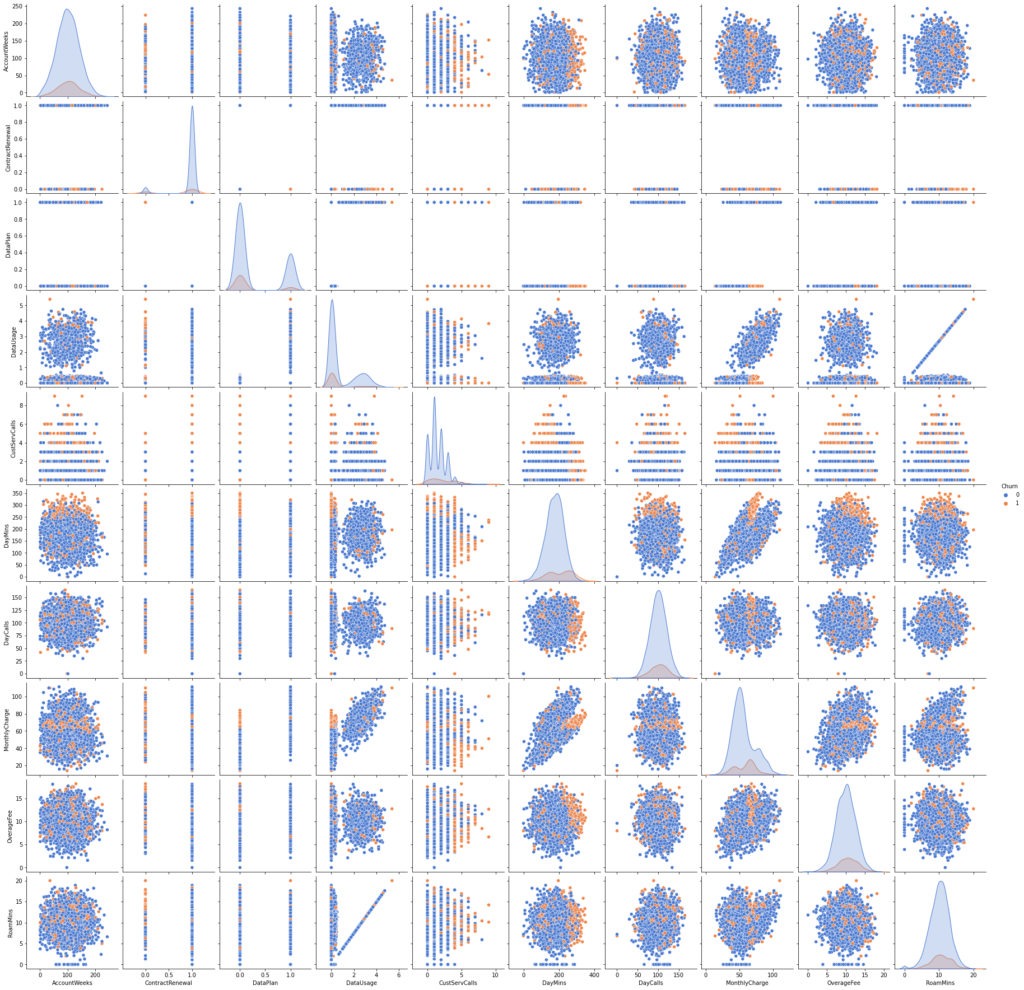
Histograms of the churn prediction dataset separated by prediction label (red=churn, blue= no churn)
We can see that the data distribution for several attributes looks quite good and resembles a normal distribution, for example, for OverageFeed, DayMins, and DayCalls. However, the distribution for the prediction label is unbalanced. This is because more customers remain with their contract (prediction label class = 0) than those that cancel their contract (prediction label class = 1).
Step #3 Data Preprocessing
The next step is to preprocess the data. I have reduced this part to a minimum to keep this tutorial simple. For example, I do not treat the unbalanced label classes. However, this would be appropriate to improve the model performance in a real business context. The imbalanced data is also why I chose a decision forest as a model type. Decision forests can handle unbalanced data relatively well compared to traditional models such as logistic regression.
The following code splits the data into the train (x_train) and test data (x_test) and creates the respective datasets, which only contain the label class (y_train, y_test). The ratio is 0.7, resulting in 2333 records in the training dataset and 1000 in the test dataset.
# Create Training Dataset
x_df = train_df[train_df.columns[train_df.columns.isin(['AccountWeeks', 'ContractRenewal', 'DataPlan','DataUsage', 'CustServCalls', 'DayCalls', 'MonthlyCharge', 'OverageFee', 'RoamMins'])]].copy()
y_df = train_df['Churn'].copy()
# Split the data into x_train and y_train data sets
x_train, x_test, y_train, y_test = train_test_split(x_df, y_df, train_size=0.7, random_state=0)
x_train AccountWeeks ContractRenewal DataPlan DataUsage CustServCalls DayCalls MonthlyCharge OverageFee RoamMins
2918 58 1 0 0.00 4 112 53.0 13.29 0.0
1884 51 0 1 3.32 2 60 74.2 10.03 12.3
2823 87 1 0 0.00 2 80 50.0 9.35 16.6
2319 83 1 1 2.35 3 105 91.5 12.65 8.7
2980 84 1 0 0.00 3 86 62.0 13.78 14.3
... ... ... ... ... ... ... ... ... ...
835 27 1 0 0.00 1 75 31.0 10.43 9.9
3264 89 1 1 1.59 0 98 50.9 10.36 5.9
1653 93 0 0 0.00 1 78 42.0 10.99 11.1
2607 91 1 0 0.00 3 100 53.0 11.97 9.9
2732 130 0 0 0.00 5 106 68.0 18.19 16.9Step #4 Fit an Optimized Decision Forest Model for Churn Prediction using Grid Search
Now comes the exciting part. We will train a series of 36 decision forests and then choose the best-performing model. The technique used in this process is called hyperparameter tuning (more specifically, grid search), and I have recently published a separate article on this topic.
The following code defines the parameters the grid search will test (max_depth, n_estimators, and min_samples_split). Then the code runs the grid search and trains the decision forests. Finally, we print out the model ranking along with model parameters.
# Define parameters
max_depth=[2, 4, 8, 16]
n_estimators = [64, 128, 256]
min_samples_split = [5, 20, 30]
param_grid = dict(max_depth=max_depth, n_estimators=n_estimators, min_samples_split=min_samples_split)
# Build the gridsearch
dfrst = RandomForestClassifier(n_estimators=n_estimators, max_depth=max_depth, min_samples_split=min_samples_split, class_weight='balanced')
grid = GridSearchCV(estimator=dfrst, param_grid=param_grid, cv = 5)
grid_results = grid.fit(x_train, y_train)
# Summarize the results in a readable format
results_df = pd.DataFrame(grid_results.cv_results_)
results_df.sort_values(by=['rank_test_score'], ascending=True, inplace=True)
# Reduce the results to selected columns
results_filtered = results_df[results_df.columns[results_df.columns.isin(['param_max_depth', 'param_min_samples_split', 'param_n_estimators','std_fit_time', 'rank_test_score', 'std_test_score', 'mean_test_score'])]].copy()
results_filteredstd_fit_time param_max_depth param_min_samples_split param_n_estimators mean_test_score std_test_score rank_test_score
28 0.004742 16 5 128 0.931415 0.006950 1
27 0.002620 16 5 64 0.925848 0.008177 2
29 0.015711 16 5 256 0.925846 0.006156 3
20 0.006258 8 5 256 0.923704 0.007961 4
19 0.001816 8 5 128 0.921988 0.006458 5
18 0.002161 8 5 64 0.919847 0.007716 6
31 0.003728 16 20 128 0.902690 0.011642 7
30 0.002057 16 20 64 0.901836 0.009789 8
32 0.004940 16 20 256 0.899691 0.009813 9
21 0.001994 8 20 64 0.898408 0.008710 10
22 0.003761 8 20 128 0.897121 0.007529 11
23 0.003828 8 20 256 0.895833 0.009159 12
33 0.003798 16 30 64 0.885546 0.010394 13
26 0.005560 8 30 256 0.885541 0.014937 14
...The best-performing model is model number 29, which scores 92,7 %. Its hyperparameters are as follows:
- max_depth = 16
- min_samples_split = 5
- n_estimators 256
We will proceed with this model. So what does this model tell us?
We can gain an overview of the distributions of our customers according to their churn probability. Just use the following code:
# Predicting Probabilities
y_pred_prob = best_clf.predict_proba(x_test)
churnproba = y_pred_prob[:,1]
# Create histograms for feature columns separated by prediction label value
sns.histplot(data=churnproba)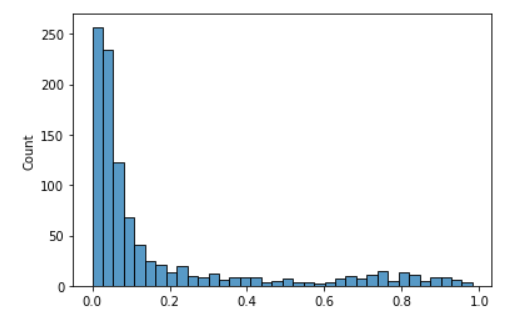
Customer Base According to their Churn Rate
Customers who tend to churn have a churn probability greater than 0.5. They are further to the right in the diagram. So, we don’t have to worry about the customers on the far left (<0.5).
Step #5 Best Model Performance Insights
Let’s take a more detailed look at the performance of the best model. We do this by calculating the confusion matrix.
If you want to learn more about measuring the performance of classification models, check out this tutorial.
# Extract the best decision forest
best_clf = grid_results.best_estimator_
y_pred = best_clf.predict(x_test)
# Create a confusion matrix
cnf_matrix = confusion_matrix(y_test, y_pred)
# Create heatmap from the confusion matrix
class_names=[False, True]
tick_marks = [0.5, 1.5]
fig, ax = plt.subplots(figsize=(7, 6))
sns.heatmap(pd.DataFrame(cnf_matrix), annot=True, cmap="Blues", fmt='g')
ax.xaxis.set_label_position("top")
plt.tight_layout()
plt.title('Confusion matrix')
plt.ylabel('Actual label'); plt.xlabel('Predicted label')
plt.yticks(tick_marks, class_names); plt.xticks(tick_marks, class_names)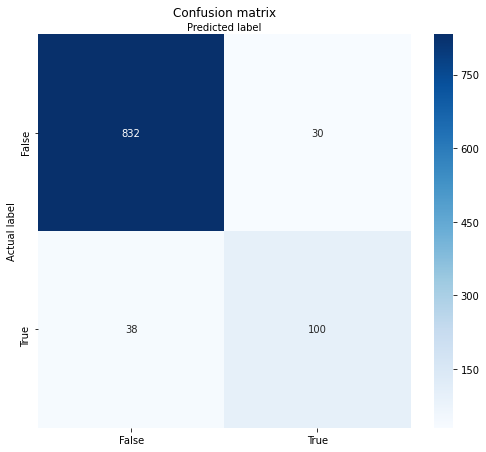
From 1000 customers in the test dataset, our model correctly classified 100 customers as churn candidates. For 832 customers, the model accurately predicted that these customers are unlikely to churn. In 30 cases, the model falsely classified customers as churn candidates, and 38 were missed and falsely classified as non-churn candidates. The result is a model accuracy of 93,2 % (based on a 0.5 threshold).
Step #6 Permutation Feature Importance
Now that we have trained a model that gives good results, we want to understand the importance of the model’s features. With the following code, we calculate the Feature Importance score. Then we visualize the results in a barplot.
# Load the data
r = permutation_importance(best_clf, x_test, y_test, n_repeats=30, random_state=0)
# Set the color range
clist = [(0, "purple"), (1, "blue")]
rvb = mcolors.LinearSegmentedColormap.from_list("", clist)
colors = rvb(data_im['feature_permuation_score']/len(x_test.columns))
# Plot the barchart
data_im = pd.DataFrame(r.importances_mean, columns=['feature_permuation_score'])
data_im['feature_names'] = x_test.columns
data_im = data_im.sort_values('feature_permuation_score', ascending=False)
fig, ax = plt.subplots(figsize=(16, 5))
sns.barplot(y=data_im['feature_names'], x="feature_permuation_score", data=data_im, palette='nipy_spectral')
ax.set_title("Random Forest Feature Importances")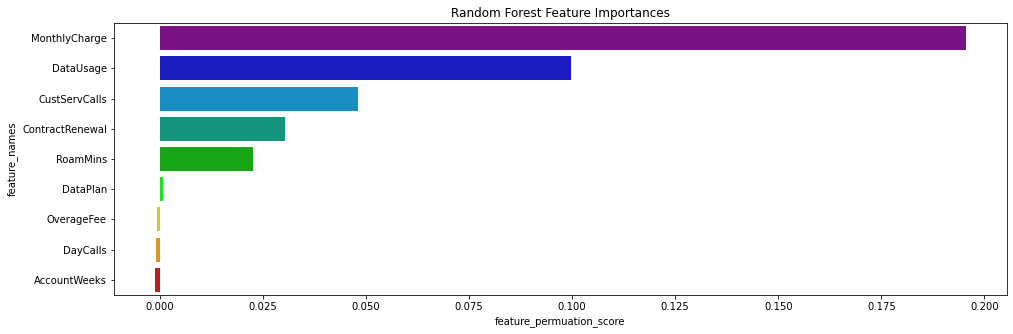
The feature ranking can provide the starting point for deeper analysis. As we can see, the most important features are the monthly fee, data usage, and customer service calls (CustServCalls). Of particular interest is the importance of customer service calls, as this could indicate that customers who encounter customer service have negative experiences.
Summary
This article has shown how to implement a churn prediction model using Python and scikit-learn Machine Learning. We have calculated the permutation feature importance to analyze which features contribute to the performance of our model. You have learned that permutation feature importance can provide data scientists with new insights into the context of a prediction model. Therefore, the technique is often a good starting point for forthleading investigations.
I am always interested in improving my articles and learning from my audience. If you liked this article, show your appreciation by leaving a comment. And if you didn’t, let me know too. Cheers
Sources and Further Reading
- Andriy Burkov (2020) Machine Learning Engineering
- Oliver Theobald (2020) Machine Learning For Absolute Beginners: A Plain English Introduction
- Aurélien Géron (2019) Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems
- David Forsyth (2019) Applied Machine Learning Springer
The links above to Amazon are affiliate links. By buying through these links, you support the Relataly.com blog and help to cover the hosting costs. Using the links does not affect the price.
And if you are interested in text mining and customer satisfaction, consider taking a look at my recent blog about sentiment analysis:
https://www.relataly.com/simple-sentiment-analysis-using-naive-bayes-and-logistic-regression/2007/



